
SimCSE:Contrastive Learning 在 NLP 的應用,Sentence Embedding 的新 SOTA
Abstract:
去年(2020)在 Computer Vision 領域,Contrastive Learning(CL,對比學習)顯得風風火火,許多用上 Contrastive Learning 概念的模型相繼被提出,最出名的例如:Google 提出 SimCLR,Facebook 提出 MoCo、MoCo V2。Contrastive Learning 可套用於不同的學習上,不管是 supervised 或 unsupervised,如:SimCLR 藉由 Self-Supervised Learning(SSL,自監督學習),不只不需要人工標註的資料集即可訓練,表現也相當出色,在 ImageNet 上甚至能跟使用 Supervised Learning 的模型表現相當。那麼既然 Contrastive Learning 這麼厲害,在 NLP 的領域一定也有用上的地方對吧?答案是是的,今天筆者就要來介紹 SimCSE: Simple Contrastive Learning of Sentence Embeddings 這篇論文。
Introduction
SimCSE 關注的問題是 universal sentence embeddings,這在 NLP 領域是個基礎且重要的問題。SimCSE 提出一個應用 Contrastive Learning 的訓練方法,來訓練預訓練語言模型(如:BERT 或 RoBERTa),可以使用不管是 unlabeled 或 labeled data 來訓練 sentence embeddings。在使用 unlabeled data 進行 unsupervised learning 的情況下,SimCSE 在 STS(Semantic textual similarity)任務的表現上,不只是遠超其它之前提出的 unsupervised models,甚至能超越 supervised models,使用 labeled data 進行 supervised learning 則更不用說了,穩穩的成為 STS 任務的新 SOTA。如果將 SimCSE 訓練出的模型,遷移到其它任務進行微調,則表現也能比之前提出的其它方法有相當抑或好上一點的表現。
接下來筆者將慢慢講解 SimCSE,包括:
- Contrastive Learning
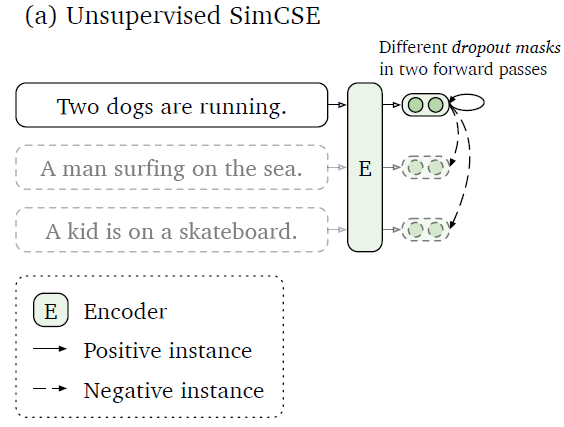
- Unsupervised SimCSE
- Supervised SimCSE
- Result
- Conclusion
Contrastive Learning
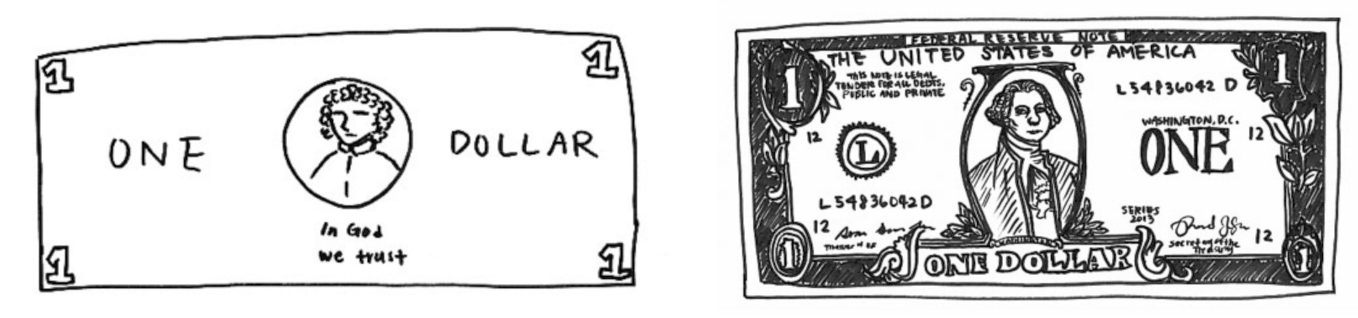
左:憑記憶畫出來的美元鈔票。右:在有美元鈔票的情況下畫出來的圖。
圖(2)說明了一件事,即使我們見過很多次鈔票,也無法重現出完美的鈔票,但是我們仍然能夠藉由某些關鍵特徵,就能輕易地辨別是否為鈔票。藉此,也就表示其實模型並不需要記住每一個細節,只要能擷取出關鍵特徵,就可以區分不同的東西,這就是 Contrastive Learning 的核心思想。

這裡藉由 SimCLR 圖(3)是怎麼做的,來簡單了解 CL。(1)先 sample 一些 data(batch);(2)對 batch 裡的 data 做不同的 augmentation;(3)一樣的 data 的 representation 要互吸,不一樣的要互斥,簡易流程就是這樣。一樣要拉近,不一樣要拉遠,這就是 CL 的目標。
接下來我們就來看看 SimCSE 是怎麼設計 CL 的訓練。
Unsupervised SimCSE
Unsupervised SimCSE 最關鍵的地方就是對如何建構 positive pair 的回答,對於 CV 領域有很多方法,如:cropping、flipping、distortion、rotation 這些 augmentation method,NLP 在近年也有許多方法被提出,如:word deletion、reordering、substitution。但作者發現這些方法反而會傷害到模型的表現,對此作者最後給出的答案非常簡單,那就是 dropout,dropout 可以作為 minimal data augmentation,並達到比之前其它的 augmentation 方法更好的表現。
所以要建構 positive pair 就非常簡單,作者直接利用原始 Transformer 裡的 dropout,讓一個句子分別通過模型兩次,因為 dropout 的關係,產出的兩個 sequence embedding 就會有些許的不同,從而變成一對 positive pair。接下來就是照上面所敘述的 CL 概念進行訓練就好。
Supervised SimCSE
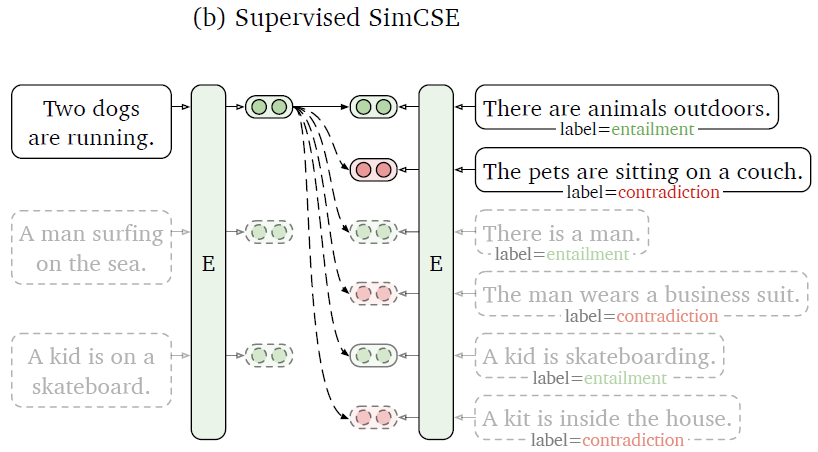
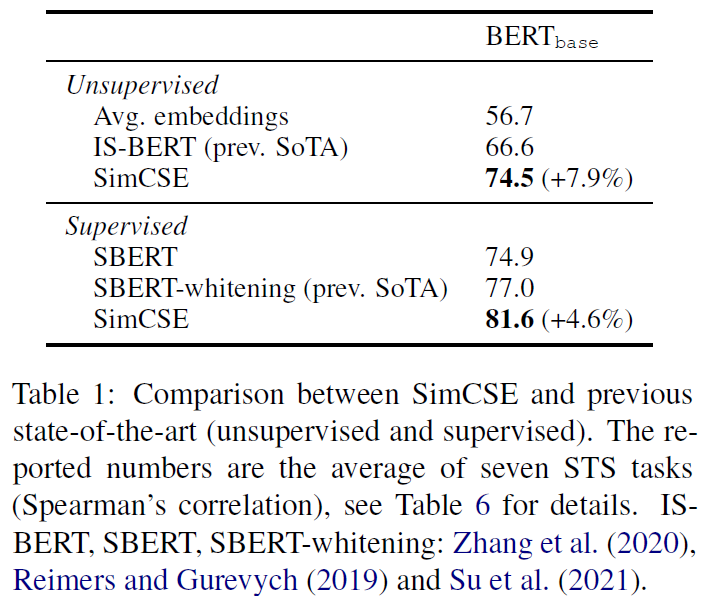
剛剛我們提到作者提出使用 dropout 來建構 positive pairs,並進行 unsupervised learning。接下來作者也研究了,如果我們使用 supervised datasets 來進行 supervised learning 能不能得到更好的表現?
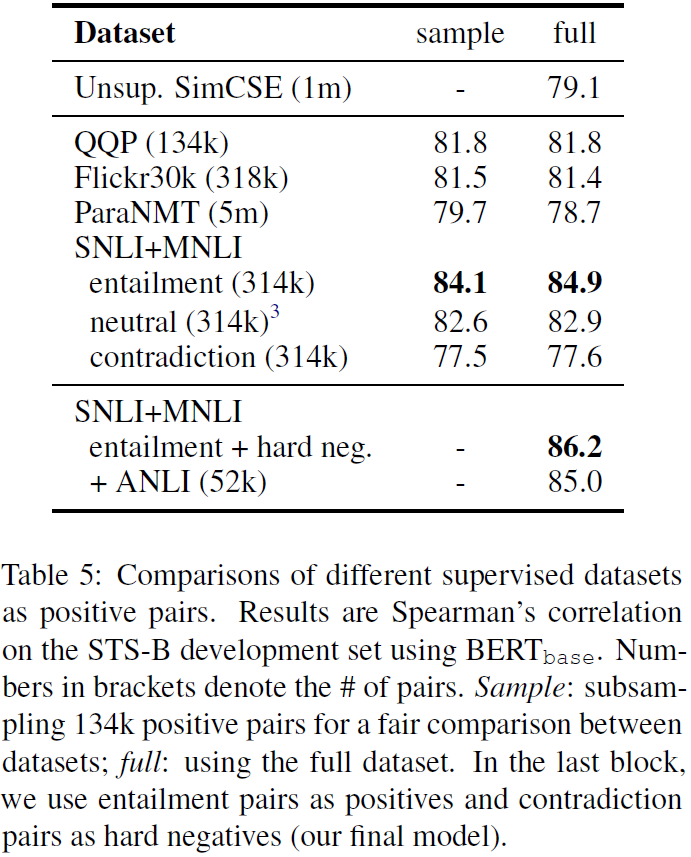
圖(6)回答了上述的問題,作者實驗了各種不同的 supervised dataset ,結果顯示使用 supervised dataset 訓練的確有效提高了模型的表現。並且作者提出利用 NLI datasets 的 contradiction pairs 當作 hard negative pairs,可以更進一步提高表現。作者也發現之前的方法(如:Sentence-BERT、StackSeq2Seq)常使用的 dual encoder framework 反而會降低模型的表現。
Results
最後我們來看看 SimCSE 的各項表現。
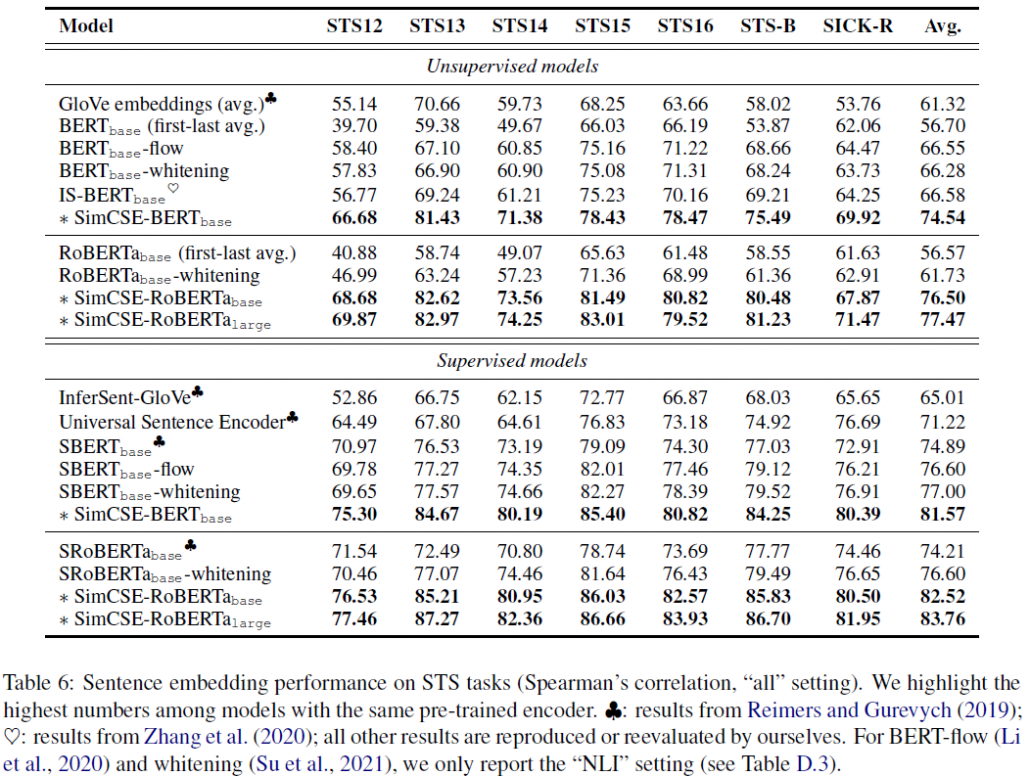
圖(7)顯示我們同時評估 supervised 和 unsupervised SimCSE 在每一個 STS 任務的表現。不管是哪一種 learning,SimCSE 在每個任務上表現相較之前都有所提升,綜合表現遠超之前的模型。SimCSE-RoBERTa_large 在只使用 unsupervised learning 下,表現甚至已經跟之前的 supervised model 旗鼓相當。
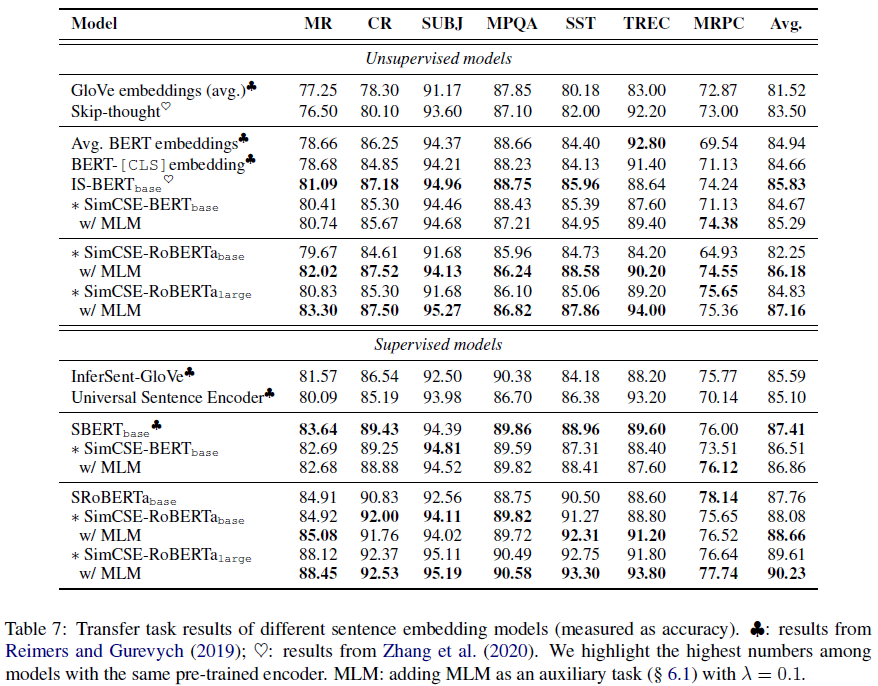
圖(9)顯示當我們遷移 SimCSE 去做其它 NLP 的下游任務,SimCSE 都能有相當或是更好一點的表現。作者也發現,如果在訓練時加入 MLM(Masked Language Model,克漏字)一起訓練,根據下游任務的不同,可能會有幫助或是傷害。
論文還有很多有趣的實驗,像是 pooler(如何產出 sequence embedding)的選擇、batch size、其它 unsupervised 方法在訓練的表現等等,因為篇幅關係,筆者就只取一部分講解,有興趣的人可以去看看原始論文。
Conclusion
SimCSE 提出利用 Contrastive Learning 進行訓練,可以使用不管是 Supervised 或 unsupervised learning 進行訓練,方法簡單暴力,在 STS 任務上成為新 SOTA。

發表評論
Want to join the discussion?Feel free to contribute!