
Mixed Precision Training(Pytorch 範例程式)
Mixed precision training 是由百度與 NVIDIA 發表於 ICLR 2018 的論文,其提出一種訓練方法,使得在使用 half-precision(FP16) 訓練模型的情況下,也能達到與使用 single-precision(FP32) 訓練相當的表現,且得到加快訓練速度與降低顯存需求的效果。
Motivation
在當今我們使用的模型變得越來越大,資料也越來越多,結果就是需要更高的算力與更多的顯存來訓練模型。
但當我們的資源不敷使用,銀彈也不夠直接買新設備時該怎麼辦呢?
這個時候就需要使用一些技法來設法降低資源需求,從而達到我們的目標,而 mixed precision training 就是其中一種方法。
影響 deep learning model performance 之因子有以下三種:
- arithmetic bandwidth
- memory bandwidth
- latency
降低使用的精度,可以降低其中兩種因子的影響。
memory bandwidth 的壓力會降低,因為我們只需要更少的 bits 來存儲同樣的參數。
計算時間也會跟著降低,因為降低了計算的精度,從而得到了更高的 throughput。
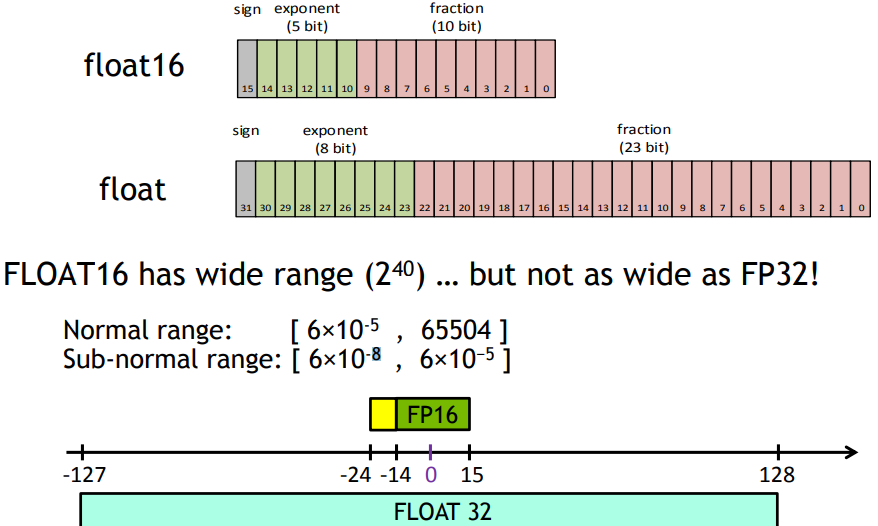
不過降低精度也不是沒有副作用的,因為能夠表達的數值比原本更小。
由下圖所見,以 FP16 為例,它就只包含 FP32 的一半範圍,當我們需要使用到超過 FP16 的表達範圍時,便會產生問題,所以才需要提出 mixed precision training。
Implementation
論文將使用 half-precision(FP16) 來訓練,而為了避免 FP16 可表達數值範圍較小產生的問題,利用了三種方法來避免模型表現下降:
- fp32 master copy of weights
- loss scaling
- arithmetic precision
FP32 Master Copy of Weights
在 mix precision training 中,weights、activations、gradients 都使用 FP16 儲存,並且有一份使用 FP32 儲存的 weight,我們稱它為 FP32 master weights。
訓練流程為,在每一次疊代開始時, FP32 的 weight 會被縮成 FP16,在經過 forward 跟 backward 之後,會得到 weight gradient,利用它去更新 FP32 的 weight,如此循環。
這樣我們可以保持相近於使用 FP32 網路的精確度,並對比使用 FP32 訓練,只需一半的儲存跟算力需求。
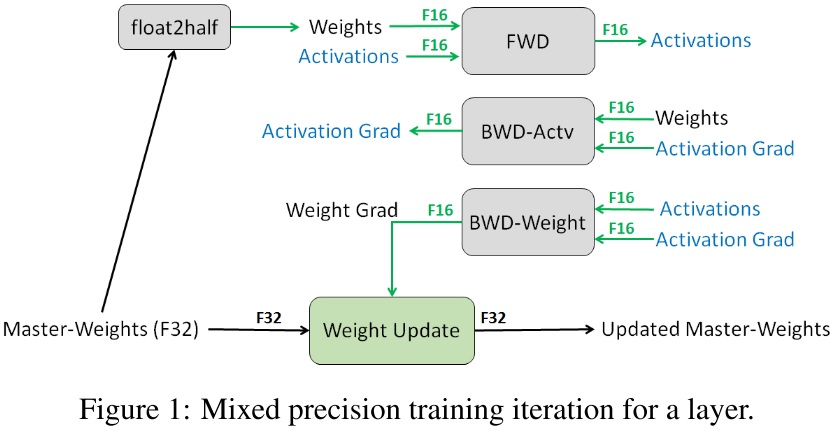
有兩個理由使我們需要 FP32 master weights。
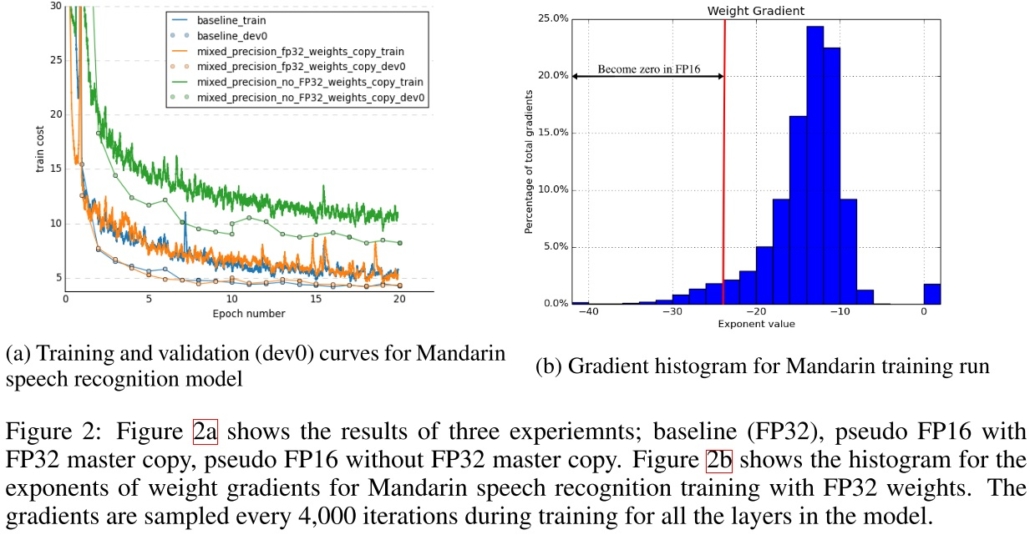
第一,當我們的 weight gradient 乘上 learning rate 太小了,使之無法表示於 FP16,那就會變成零,weight 就無法更新了,由下圖可以看到約有 5% 的 weight gradient 小於 FP16 可表示的範圍而變成 0。
第二,當要更新的 weight 的值太大,即使要更新的 weight 值可以用 FP16 表示,當它更新的時候也會因為加法在進位的情況下,同樣使值變成 0。使用 FP32 weight 來更新則可避免遇到這些問題。
論文中也做了個實驗,訓練了一個模型,在使用與不使用 FP32 master weights 的情況下,對比使用 FP32 的收斂情況,由下圖可以看到使用 FP32 master weights 相比直接使用 FP32 有很相近的效果,而不使用 FP32 master weights 訓練效果就差非常多了。
Loss Scaling
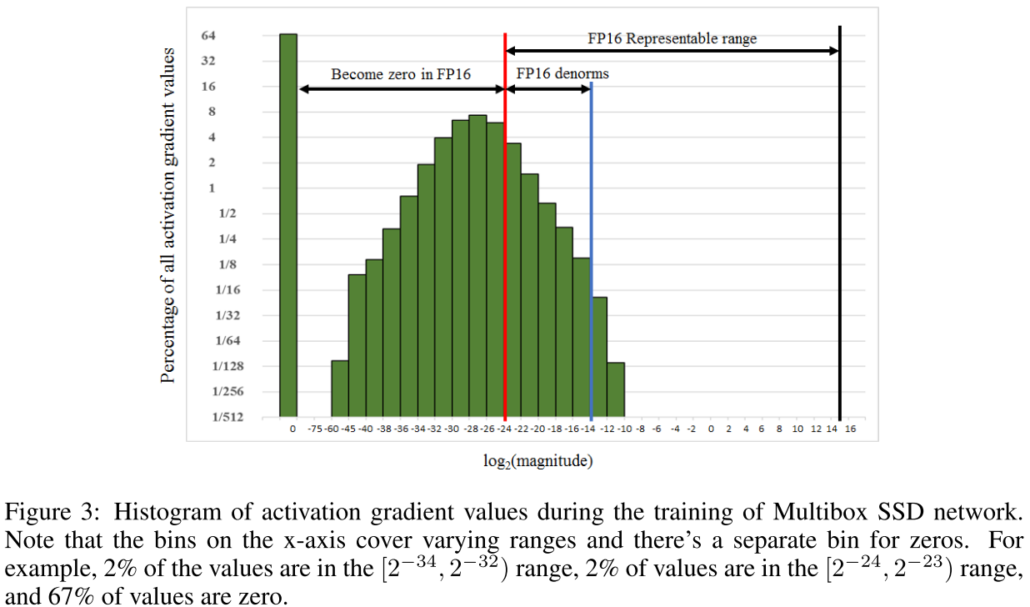
論文中指出大多數的 gradient 是負指數。並且做了個實驗來驗證,作者訓練了一個網路並且撈出每一層的 activation gradient 畫成圖,由下圖可以看到,大部分的 gradient 都是負的,並且很多小於 FP16 的表示範圍而變成了 0,另一個重要的部分則是,有一大部分 FP16 的可表示範圍沒有任何 gradient 的,這個就成了可以使用 loss scaling 的地方。
loss scaling 的想法很簡單,既然大多數 gradient 都很小,超過了 FP16 的表示範圍,那就乘上一個值讓它先變大,在更新時再縮回來不就好了。
具體來說,就是當 forward 計算出 loss 之後,把 loss 乘上一個值,這樣在 backward 時,就可以確保所有 gradient 都被一致的縮放。
然後在最後要更新 weight 時,我們在把 gradient unscaled 回來。如此就很簡單的減緩了上述的問題。
Arithmetic Precision
大多數的 deep learning network 主要使用以下三種計算:vector dot-products、reductions 與 point-wise operations。
作者提到,他們發現有些網路為了保持模型的準確度,需要將 FP16 相乘時累加到 FP32,然後在寫進內存前縮回 FP16。
在現在新的 NVIDIA GPU 上,NVIDIA 新增了 Tensor Cores,原生支援了這種計算。
Conclusion:
讓我們總結一下 mixed precision training 的流程:
- 使用 FP32 存 master copy of weights
- 在每次疊代
- copy 一個 FP16 的 weights
- Forward propagation(FP16 weights and activations)
- 把 loss 乘上 scaling factor S
- Backward propagation(FP16 weights, activations, and their gradients)
- 把 weight gradient 乘上 1/S
- 完成 weight 的更新
這裡就不細講實驗結果了,只要知道作者實驗了很多不同的網路,並且都達到與使用 FP32 訓練差不多的準確度就好,有興趣的人可以去察看原始論文。
Code
最後在 pytorch 1.6 終於也原生支援了 mixed precision training,而不用再使用 Nvidia 出的 apex 來做,簡單了許多。
這裡也放上最基礎的在 pytorch 使用 mixed precision training 的方法。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as dset
from torchvision import datasets, transforms, models
from torch.cuda.amp import autocast, GradScaler
# create transform
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),]
)
# Data
trainSet = datasets.MNIST(root='MNIST', download=True, train=True, transform=transform)
trainLoader = dset.DataLoader(trainSet, batch_size=64, shuffle=True)
# Model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.base = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
)
self.fc = nn.Linear(32*7*7, 10)
def forward(self, input):
feature = self.base(input)
feature = feature.reshape(feature.size(0),-1)
output = self.fc(feature)
output = nn.functional.log_softmax(output, dim=1)
return output
model = Model().to('cuda:0')
optimizer = optim.SGD(model.parameters(), lr=1e-3)
criterion = nn.NLLLoss()
scaler = GradScaler()
for epoch in range(10):
for input, target in trainLoader:
input, target = input.to('cuda:0'), target.to('cuda:0')
optimizer.zero_grad()
with autocast():
output = model(input)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
我們簡單宣告了一個模型並使用 MNIST 資料集進行訓練,基本上對比原本的寫法,只需要加上幾行 code 就可以自動完成,是不是很方便呢。
如果想知道更多,可以去看看官方的 文件。


發表評論
Want to join the discussion?Feel free to contribute!