



ChatGPT 是一個人工智慧聊天機器人程式,使用基於 GPT-3.5 架構的大型語言模型並透過強化學習進行訓練。
由 OpenAI 開發,於2022年11月推出的 ChatGPT,不但能聊天,還能寫程式、也能寫論文😮
ChatGPT 究竟到底有多厲害呢?來看看微軟的 AI 領域 MVP怎麼說!
本文已取得原著 大魔術熊貓工程師 同意轉載於逢甲大學人工智慧研究中心,未經同意者請勿任意轉載!
文/ Ko Ko
過年期間回南部老家,被許多親戚朋友問說:身為微軟的 AI 領域最有價值專家,你怎麼看 ChatGPT 呢?
被問了很多類似的問題,很多討論很多反饋,於是整理成這篇文章來闡述我目前的看法。
![]() :ChatGPT 絕對是個 Game Changer,但我一部份同意卷積神經網路之父 Le Cun 的看法,ChatGPT 並不是特別創新(原文: ChatGPT is not particularly innovative)。
:ChatGPT 絕對是個 Game Changer,但我一部份同意卷積神經網路之父 Le Cun 的看法,ChatGPT 並不是特別創新(原文: ChatGPT is not particularly innovative)。
這是真的,ChatGPT 在 AI 的技術上並沒有特別大的突破。Open AI 在 ChatGPT 所採用的技術,很大部分是多年前就發表的 transformer 的架構上,再加上一些手法包含也是已經出來很久的 reinforcement learning 等,整體看下來確實是沒有特別大的技術面突破。
但是 ChatGPT 絕對是個 Game Changer。用當年哀鳳剛推出時來舉例,那時候大家都在噴說:觸控螢幕不是新東西、手機不是新東西、手機上網也不是新東西、隨身聽音樂不是新東西、手機有個人助理的功能更加不是新東西(黑莓機早就有了!)。做出哀鳳確實沒有太多突出的技術突破,但是哀鳳最厲害的地方就是把這些所有的技術都整合得很好,好到無法忽視,後來成為蘋果最成功的產品之一,連我寫 Android app 出身的都改用哀鳳了。
ChatGPT 就像哀鳳一樣,但是把許多現有的 AI 技術都整合與應用得非常好,好到讓全世界的驚豔,甚至恐慌。即使它真的沒太多技術突破,我很看好也很期待 ChatGPT 下一步的發展。
![]() :絕對會,以後絕對會有很多工作被 AI 淘汰掉。這部分可以去參考李開復的論點,他有畫幾張象限圖,可以說明得非常清楚。
:絕對會,以後絕對會有很多工作被 AI 淘汰掉。這部分可以去參考李開復的論點,他有畫幾張象限圖,可以說明得非常清楚。
基本上會被淘汰掉的工作性質,就是弱社交,以及其他屬性如機械化操作、缺乏創意缺乏決策等。
![]() :是的,一定會有一大部分技能低下的軟體工程師會被淘汰,但是善用 ChatGPT 的工程師或團隊會有更多的產出。
:是的,一定會有一大部分技能低下的軟體工程師會被淘汰,但是善用 ChatGPT 的工程師或團隊會有更多的產出。
舉個例子,敏捷開發在談組織團隊那部份,有提到團隊成員最好有個 generalizing specialist,也就是具備多種職務技能所需之專業的工程師。這類成員可以執行多種任務,以減少人員切換時的風險,或是工作負載的瓶頸等。
這類人才通常稱為梳型(Comb-shaped)人才,和 T 型與 𝝅 型人才不一樣,梳子是有更多專精的技能。然而現實生活,你很難找到具備多種職務技能所需之專業的工程師。
但是透過 ChatGPT 就不一樣了。例如說甲工程師專精後端,但對於容器技術只有一點點熟悉,甲工程師就可以透過 ChatGPT 就有機會幫團隊好好寫好一個 dockerfile 了。甲工程師有多個不是那麼專精的技能,透過 ChatGPT 就可以把多個不是那麼專精技能,變得堪用,甚至甲工程師也可以透過和 ChatGPT 與交叉查找資料(因為 ChatGPT 還是會出錯,還是建議不熟的專業要再核實過)的過程中,好好學習容器技術,讓自己更容易成為梳形人才。
所以懂得好好利用 ChatGPT 的工程師、和不懂得利用的工程師,差距會愈來愈遠。對於團隊來說,也能更快培養技能更多面向的工程師,前提是好好和 ChatGPT 交互與學習。就像「深度工作力」這本書第一章所說的:能與智慧機器一起工作並發揮創造力的人,在這個時代會特別有優勢。
![]() :去讀我寫的系列文 。
:去讀我寫的系列文 。
https://ithelp.ithome.com.tw/users/20120030/ironman/5515
.編按:2022 iThome 鐵人賽 變形金剛與抱臉怪—NLP 應用開發之實戰
這系列文主要在講當代自然語言處理的範疇、原理和技術,並使用了一個現在全球最主流的框架:hugging face。同時也是繁體中文圈第一個很完整討論 hugging face 的系列文。
很重要的一點是,ChatGPT 是通用型的 AI ,還不是特用型的。例如說你問它國泰銀行的好市多卡該怎麼辦,它沒有針對國泰銀行的信用卡資料做學習,它不知道。
目前 Open AI 還沒有開放給大家做 transfer learning。一旦可以用 ChatGPT 做 transfer learning 後,就可以很容易來做特用型的 AI 了。大家一定都對於各大金融業目前推出的客服 Chatbot 感到很難用,都想要直接聯絡真人客服。因為這類 Chatbot 的大部份還是基於 intent 和 entity 的技術來做的,這種技術要做到非常的細緻是很不容易的。可是如果可以用 ChatGPT 做 transfer learning 的話,客服 Chatbot 就有可能做到跟 ChatGPT 差不多好。
所以先去讀我的系列文,了解 transfer learning 是怎麼做的,以及其他自然語言處理的知識吧!
![]() :
:
朋友 A 快要論文口試了,用 ChatGPT 來做口試的攻防練習吧!
朋友 B 快要生小孩了很焦慮,跟 ChatGPT 聊聊天吧!
朋友 C 這段程式不會寫,叫 ChatGPT 幫忙寫程式吧!
朋友 D 忘記冰與火之歌的劇情了,用 ChatGPT 來幫忙回憶吧!
![]() :這個我們下期特別寫一篇來跟大家講解。
:這個我們下期特別寫一篇來跟大家講解。
結論就是,一起擁抱 ChatGPT 吧!用它來學習、創造、工作,以及做更多更多的事。![]()
![]()
![]()
P.S. 本文真的是我自己寫的,不是用 ChatGPT 產出的。
(本文已取得原著 創新拿鐵 授權轉載於逢甲大學人工智慧研究中心,未經同意者請勿任意轉載!)
文/陳蔚銘

「人工智慧」、「大數據」是近年越來越常見的流行詞,而這股風潮漸漸從科技產業吹向傳統產業,尤其在吃、喝兩大領域,無論是百年老店「可口可樂」、美國威士忌新創「Bespoken Spirits」或是來自俄國的披薩新創「Dodo Pizza」都嘗試著解答一個疑問:如果在美食、美酒裏頭加入一點科技味,得到的結果會是「驚喜」還是「驚嚇」?
創新點:將新潮科技應用在傳統飲食產業,進而創造出破壞式創新。
本文三大重點:1. 必勝客為惡搞披薩道歉,這間公司卻用人工智慧烤出古怪「開源披薩」。 2. 美酒越陳越香,用機器學習加速威士忌熟成。 3. 可口可樂用群眾智慧找出汽水的「黃金比例」。
「Dodo Pizza」是俄羅斯最大的披薩連鎖餐廳,在全球13個國家有652間分店,他們最大的特色就是高度科技化、透明化的經營方式:在他們的網站上,可以看到所有分店即時的銷售成績。
 (圖片來源:Dodo Pizza)
(圖片來源:Dodo Pizza)而Dodo Pizza最大的特色,就是對選擇困難症患者而言相當不友善的多樣披薩口味選擇。而這一切,都要怪一篇學術論文。
2011年,一篇研究❮風味網絡與食物搭配原則(Flavor network and the principles of food pairing)❯,系統化地研究全球各地所有料理的組成,把抽象的口味「量化」。
舉例來說:咖啡和牛肉有102種相同的化合物、蝦子和檸檬則只有9種重複;一般而言,同質性高的食材合在一起創造出和諧的口感、同質性低的食材則有互相提味的作用。
而Dodo Pizza依據這篇論文,分析了熱門食譜網站(如Cookpad)上高達30萬份食譜,從中歸類出1,000種食材,初步分類為常見組(如番茄、雞肉、莫扎瑞拉起司)以及罕見組(如榴連、梨子、薄荷)等等。
接下來,調整「常見」和「罕見」組的比例,訓練自家人工智慧「Dodo AI」計算出少見的食材組合,卻可能會受大眾歡迎的口味。因此,從常見的「瑪格麗特」、「義式臘腸」到稀奇的「榴連章魚燒」、「薄荷火腿」口味,都可能出現在Dodo AI提供的建議當中。
基於「好東西不能只有我知道」的出發點,他們也把訓練出來的Dodo AI放在程式碼管理公司「Github」開源,所有人都可以自由使用來創造專屬的風味披薩,讓小餐廳做出大型連鎖業者做不到的口味,一起「提升全球比薩到全新的境界」。
(同場加映:幽靈廚房熱潮減退了嗎?從機器人披薩外送服務Zume裁員50%,看餐飲業的下一波變革)
「Bespoken Spirits」是間矽谷新創公司,宣稱能用機器學習的技術加速傳統威士忌釀造過程中最耗時的「陳年」階段。
 (圖片來源:Bespoken Spirits)
(圖片來源:Bespoken Spirits)傳統威士忌釀造過程會把蒸餾出的原酒裝進橡木桶,在特定的環境裡存放一段時間進行熟成。木桶的種類、存放地點的溫濕度、時間長短會決定威士忌出桶裝瓶後的香氣、顏色和風味。
而Bespoken的「活化(ACTivation)」技術,就是香氣(Aroma)、顏色(Color)和風味(Taste)的縮寫:他們收集了2萬5千種木頭小方塊,分析並記錄個別的化學成分,再把這些小木塊烘烤後磨成細粉,和蒸餾酒液一起加入大鐵桶中。接著調整溫濕度、壓力以加速熟成,再由專業品酒師寫下「花香突出」、「泥煤顯著」等評分,最後得到不同木頭比例、環境條件對應威士忌特色的配方。
藉由這樣的做法,威士忌陳年時間由「年」大幅縮短到「天」,不但避免酒液在儲存過程隨時間揮發掉的損失、也減少97%製作木桶的木材用量;最重要的是,讓許多小型釀酒商更容易創新,因為他們不再需要苦熬多年,就能做出小眾市場的差異化。
雖然非典型的釀酒方式招致許多批評,認為Bespoken破壞了這門傳承已久的手工技藝,但從成果來看,Bespoken的自有品牌已逐漸在許多世界烈酒比賽中獲得肯定。
總結而論,Bespoken以活化技術衍生的商業模式有三個主軸:
一、為釀酒商提供加速陳桶服務(maturation-as-a-service),加速資金輪動和庫存去化。
二、為零售商、餐廳或酒吧代工,提供客製化的店家招牌酒(House wine)。
三、經營自有品牌的威士忌。
(同場加映:疫情期間,股價逆勢暴漲2.5倍的波士頓啤酒)
2009年7月,可口可樂公司在全美各地陸續安裝了60幾個「Freestyle」汽水機,提供旗下品牌上百種的飲料讓消費者購買。直到今年,全美已有上萬台的Freestyle汽水機。
 (圖片來源:Coca-Cola Freestyle)
(圖片來源:Coca-Cola Freestyle)這些Freestyle汽水機除了單一飲料,還能讓顧客依照自己喜歡的口味比例,自由混合兩到三種不同風味的飲料。
而隨著行動上網普及,可口可樂也推出Freestyle APP,讓顧客搜尋附近的Freestyle汽水機、記錄自己最愛的「獨家配方」、進而和社群分享,分享達到特定數量,還能獲得徽章挑戰等等。
2019年,可口可樂舉辦「Make Your Mix」挑戰,提供一萬美元獎金,徵求顧客把自己的Freesyle配方上傳到Instagram或twitter,加上#MakeYourMixContest的hashtag之後,票選出最受歡迎的五種配方入圍決賽。
而最終,由一位波蘭移民Danuta Rybak以40%櫻桃可樂、35%美粒果檸檬汽水加上25%的櫻桃芬達的「黃金比例」勝出獲得大獎,隨後更成為可口可樂正式上市產品。
(影片來源:YouTube)
對可口可樂公司來說,從Freestyle汽水機收集到全美各地的數據,可以從中分析出各地區、年齡層、季節性的消費者喜好趨勢。相較於傳統市調方式,可口可樂設置汽水機的作法有幾項優勢:
一、即時掌握變化,有利新品研發以及分區、分眾行銷。
二、不必猜消費者可能喜歡什麼,所有選擇攤開隨選隨喝,馬上就能獲得回饋。
三、所有新產品都以既有產品為基底,不需新增產線,降低複雜度。
可口可樂公司在2019推出檸檬雪碧、橘子香草可樂的靈感就是來自多年累積的數據,同時,意識到自己的最愛可能會變成正式產品,無形中也提升粉絲對品牌的參與感。
(同場加映:一樣借助「群眾智慧」設計產品的料理社群Food52)
1. 人工智慧走入廚房!從刀削麵到米其林餐點都能為你準備
2. 人工智慧會毀滅人類?知名創投大師告訴你3件他對科技的獨到看法
3. 整理照片、分類小黃瓜… 人工智慧在個人生活上的4大應用
1. AI-Created by Dodo Analyzed 300000 Recipes to Create a Pizza Transcending Individual Tastes
2. AI in Food Processing
3. FDA AI Fish Import Screening
4. Bespoken Spirits Raises 2.6M in Seed Funding to Combine Machine-Learning and Accelerated Whiskey Aging
5. Derek Jeter Gets into the Liquor Game
6. Coca-Cola Freestyl
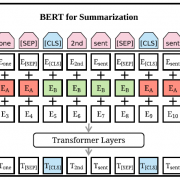
不管要解任何問題,從 BERT、ELMo、GPT 等等,這些大家琅琅上口的各種預訓練模型開始進行,在 NLP 領域基本已經變成起手式。筆者今天要介紹的論文 Text Summarization with Pretrained Encoders 也不例外,論文分析如何有效地將 BERT 應用在 text summarization task 上,以及預訓練模型對 text summarization task 的影響,並且提出一個可以做 extractive 和 abstractive models 的通用框架。
論文的 contribution 為:
接下來,筆者將先快速介紹跟 text summarization task 相關的各種名詞,幫助不熟悉此領域的讀者了解讀懂論文需要的知識,以防鴨子聽雷的狀況,之後再進入正題,熟悉的讀者則可直接跳往正題閱讀。
BERT 這個由 Google 在 2019 所提出的模型相信大家都不陌生,在提出後就刷了各種任務的榜,成了 NLP 領域無人不知無人不曉的模型。論文中對 BERT 的輸入進行了修改,讓其更好的對應 summarization task 的特性,為了對比,筆者先複習一下原版的 BERT 的輸入。
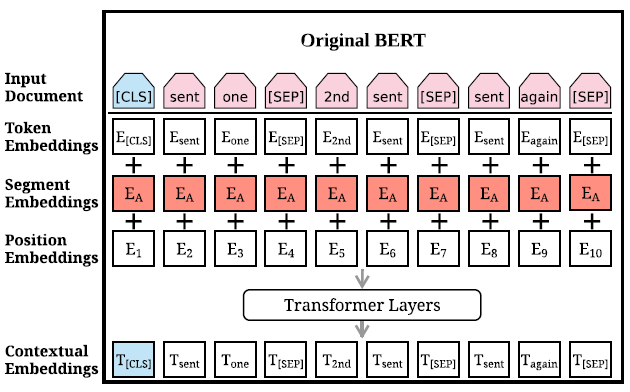
一開始要輸入的 document 會經過處理加上兩種特殊符號[CLS]與[SEP]。[CLS]插在整個 document 的頭,代表整個 document 的開始,[SEP]插在 document 中每個 sentence 的尾,用來區分不同的 sentence。經過處理後,document 表示成 \(Input \, document = [w_1, w_2, \dots , w_n]\),\(w_i\) 代表 document 裡的第 \(i\) 個 token。在 BERT 裡,每個 token \(w_i\) 總共會有三種 embedding,token embeddings 代表 token 的意思,segmentation embeddings 代表 token 屬於哪個句子,position embeddings 代表 token 在 sentence 中的位置,將這三種 embedding 相加起來就變成了 BERT 的輸入 \(X = [x_1, x_2, \dots , x_n]\),之後丟進由幾層 Transformer Layers 疊起來組成的 Encoder:
\(\widetilde{h}^l = LN(h^{l-1} + MHAtt(h^{l-1}))\)
\(h^l = LN(\widetilde{h}^l+ FFN(\widetilde{h}^l))\)
h 是 hidden states,\(h^0 = X\);LN 是 Layer normalization;MHAtt 是 multi-head attention;\(l\) 是疊幾層 Transformer Layers 的層數。最終 BERT 會輸出 \(T = [t_1, t_2, \dots , t_n]\),每個 \(t_i\) 是擁有語意資訊的 word embedding。
在 text summarization 有兩種不同的系統,分別是 extractive 與 abstractive 兩種。
extractive summarization 為藉由在文章裡找尋重要的句子,並把找出來的句子接在一起,當作這篇文章的 summary。在模型訓練上,則是當做 sentence classification 的任務,藉由分類每個句子是否為重要句子,來得到要做為 summary 的句子。
abstractive summarization 則是將原始文章餵給模型吃,並直接吐出一段 summary 的方法,是一個 sequence to sequence 的問題。abstractive 相較 extractive 困難的點為,abstractive 需要能夠產生原本不存在於文章的詞彙或句子,並且要符合語言的規則。
在上面筆者簡單複習了 BERT 與 summarization task 的兩種方式,現在就讓我們來看看如何微調 BERT,在任務上做得更好吧。
論文中指出,將 BERT 直接應用於 summarization,顯然是會有問題的。首先在做 summarization 上,我們通常會使用 sentence embedding 來做相關任務,但 BERT 的訓練方式 MLM(克漏字、填空),學習重點是放在 word embedding 上,而不是 sentence embedding ,另一個問題是即便 segmentation embeddings 可以區分不同的句子,在原始 BERT 中只有使用 sentence pair 進行訓練,就是兩個句子組合在一起,在 summarization 上,則通常需要使用大於兩個的多句子接在一起當作輸入。
鑒於上面提到的問題,論文修改了原始 BERT 的輸入方式,讓 BERT 可以更好的處理 summarization,並提出針對 summarization task 的 BERTSUM。

在 BERTSUM 中,document 裡的每一段 sentence 前面都會額外插入一個[CLS]符號,這裡這麼做有兩個目的,一個是為了凸顯個別句子(individual sentences),另一個是,作者會將這些[CLS]符號的輸出當作每段句子的 sentence embedding,用於後續的預測任務。segmentation embeddings 也被修改為 interval segment embeddings,用於更好的區分多句子,規則是 \(sent_i\) 會根據它是奇數句或偶數句來決定是 \(E_A\) 或 \(E_B\)。舉個例子,一個 document 包含 \([sent_1, sent_2, sent_3, sent_4, sent_5]\),那麼這個 document 的 segment embeddings 為 \([E_A, E_B, E_A, E_B, E_A]\)。經過這樣的設計,模型就能學習到不管是句子表示,相鄰的句子,或是整個 document 的意思。
論文中分別提出如何將 BERTSUM 應用於 Extractive 和 Abstractive Summarization 上,接下來就讓我們來一個一個看看是怎麼做的。
在 background 中,筆者介紹過 Extractive Summarization 其實就是對每個句子做二元分類,分類是否要拿來作 summary,所以我們要做的就是把每段句子的 sentence embedding 取出來並丟進分類器進行預測。論文中介紹了在 BERTSUM 上,再加入了幾層 Transformer layers 來做 Extractive Summarization 的模型,並命名為 BERTSUMEXT。整個模型構造很簡單,以下開始介紹:
在 BERTSUM 中,剛剛筆者說過每段句子的 sentence embedding 由[CLS]符號的輸出而來。因此,我們可以將 BERTSUM 的輸入看做是很多個句子,\(d\) 代表一個 document 包含句子 \([sent_1, sent_2, \dots ,sent_m]\),\(sent_i\) 是在 document 裡的第 \(i\) 個句子,第 \(i\) 個[CLS]符號的輸出寫作 vector \(t_i\) ,是 \(sent_i\) 的 sentence embedding。通過 BERTSUM 我們有了每個句子的 sentence embedding,接下來就是將它們丟進額外加入的 \(l\) 層 Transformer layers,獲取 document-level 的特徵:
\(\widetilde{h}^l = LN(h^{l-1} + MHAtt(h^{l-1}))\)
\(h^l = LN(\widetilde{h}^l+ FFN(\widetilde{h}^l))\)
h 是 hidden states,\(h^0 = PosEmb(T)\);\(T\) 代表 BERTSUM 輸出的 sentence embeddings。
模型的最後就是一個簡單的 sigmoid classifier:
\(\hat{y}_i = \sigma(W_0h_i^L+b_o)\)
\(h^L_i\) 就是 Transformer第 \(L\) 層 \(sent_i\) 的輸出。
在 Abstractive Summarization 中,這篇論文使用的模型是普通的 encoder-decoder 架構。encoder 是 pretrained 過的 BERTSUM,decoder 則是隨機初始化的 6 層 Transformer layers。這裡有個小重點,encoder 與 decoder 必須使用不同的 optimizer 來訓練,原因是,如果直接一起訓練的話,當 decoder 還在 underfitting 時,經過 pre-trained 的 encoder 可能已經 overfitting 了。因此,訓練這個網路時,encoder 會使用較小的 learning rate,decoder 則使用較大的 learning rate,讓整個訓練更穩定。這種架構與訓練方式的網路,論文稱為 BERTSUMABS。
論文中也同時提出一個兩階段式 fine-tune 方法,稱為 BERTSUMEXTABS。根據先前的經驗(Gehrmann et al., 2018; Li et al., 2018),先做 extractive summarization 可以提升模型在 abstractive summarization task 的表現,所以 BERTSUMEXTABS 會先在 extractive summarization task 上 fine-tuned encoder ,然後再在 abstractive summarization task 上 fine-tuned 第二次。這樣訓練出來的模型稱為 BERTSUMEXTABS。

論文總共實驗了三種不同的資料集,它們的 summary 風格各不相同,可能是文章的重點摘要、一句總結,或由原文剪貼而成,這樣我們就可以評估模型在不同 summary 形式下的表現。
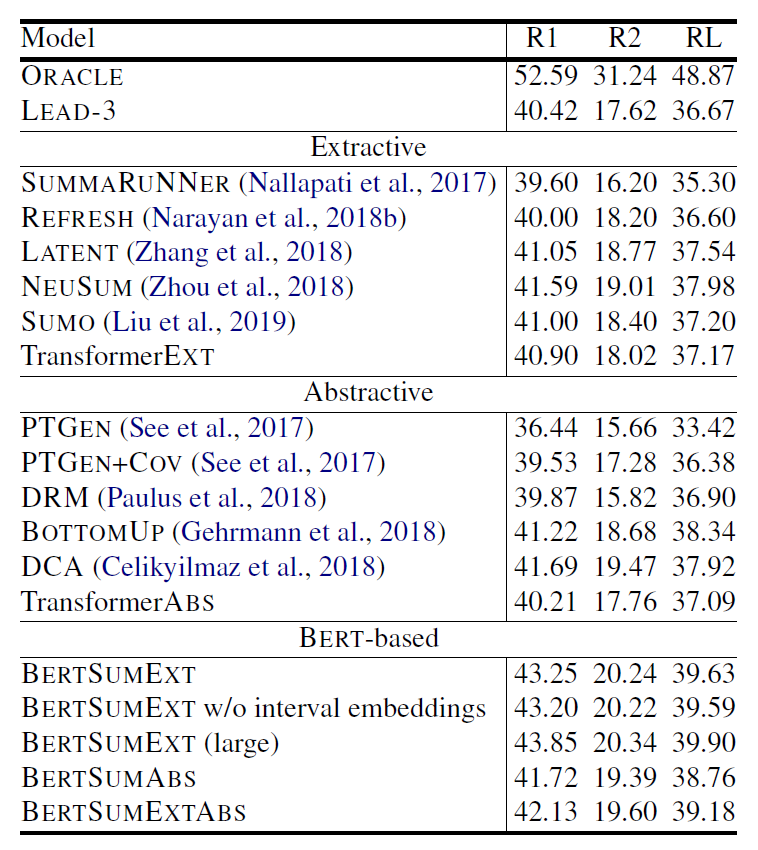
表 (1)第一行的 ORACLE 是 extractive ORACLE system,在這裡用來當作表現的 upper bound。LEAD-3 則是直接選文章的前三句當作 summary 的表現。TransformerEXT 代表架構與 BERTSUMEXT 一樣,但是沒有經過 pre-trained,直接在 summarization task 上做訓練,TransformerABS 同理。由表中可以觀察到,BERSUM 相比之前的模型表現都有提升,但也沒有提升太多,原因讓我們繼續看看別的資料集的實驗結果就會知道。
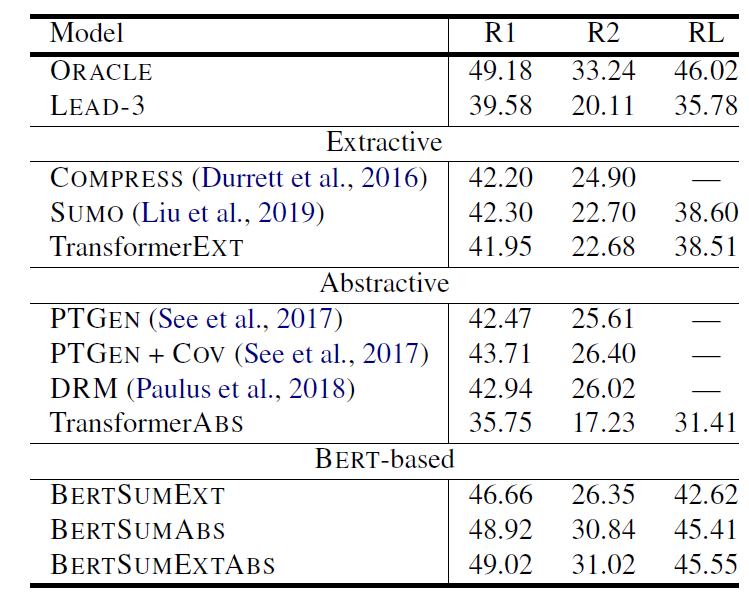
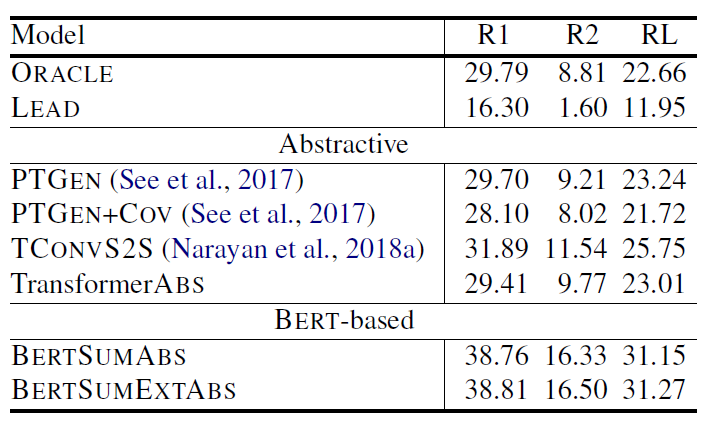
當我們一次把 BERTSUM 在 CNN/DailyMail(表 1)、NYT(表 2)跟 XSum(表 3)的表現拿出來比較,原因就很明顯了。有發現嗎?在 percent of novel bi-grams in gold summary 低的資料集,BERTSUM 的表現就顯得普通,沒有驚人的表現,跟 LEAD-3 的表現也差距不大,並且 BERTSUMEXT 會是表現較好的模型,這就顯示了因為 gold summary 可以大幅地從原文中拼貼出來,所以模型之間的表現就拉不開差距。所以在這種發現下,如果去看 BERTSUM 在 XSum 的表現,BERTSUM 的厲害就徹底展現出來了,不僅贏過了 ORACLE system,表現相比其他模型也大幅上升。
另一個值得關注的點則是 pre-trained 的重要性,對比有 pre-trained 與沒有 pre-trained 的模型,可以發現表現差距很大,尤其在 abstractive summarization 上,最多可以有超過 10% 的差距,再一次呼應論文標題的 with Pretrained Encoders 這句話。
本文帶讀者了解了 Text Summarization with Pretrained Encoders 這篇論文,其基於 BERT 進行改良,改造成適合用於 summarization task 的架構,並提出 BERTSUMEXT、BERTSUMABS、BERTSUMEXTABS 三種模型,用簡單的方式,大幅提升了 BERT 在 summarization task 上的表現。
去年(2020)在 Computer Vision 領域,Contrastive Learning(CL,對比學習)顯得風風火火,許多用上 Contrastive Learning 概念的模型相繼被提出,最出名的例如:Google 提出 SimCLR,Facebook 提出 MoCo、MoCo V2。Contrastive Learning 可套用於不同的學習上,不管是 supervised 或 unsupervised,如:SimCLR 藉由 Self-Supervised Learning(SSL,自監督學習),不只不需要人工標註的資料集即可訓練,表現也相當出色,在 ImageNet 上甚至能跟使用 Supervised Learning 的模型表現相當。那麼既然 Contrastive Learning 這麼厲害,在 NLP 的領域一定也有用上的地方對吧?答案是是的,今天筆者就要來介紹 SimCSE: Simple Contrastive Learning of Sentence Embeddings 這篇論文。
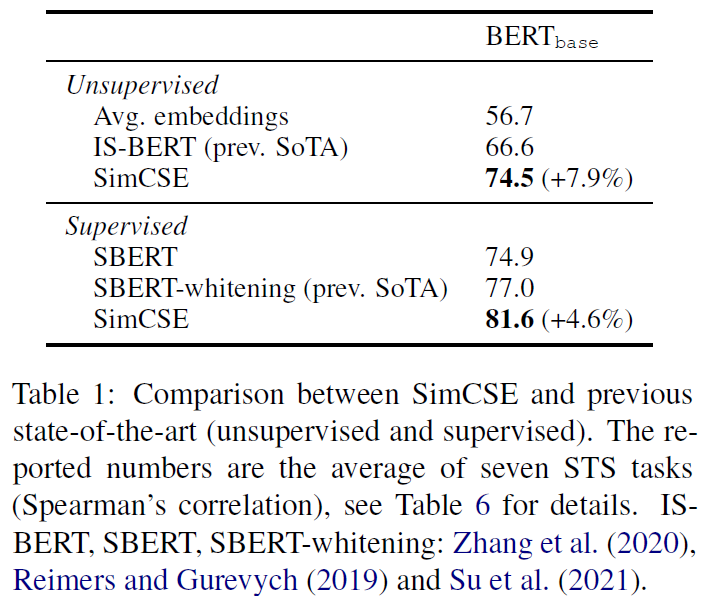
SimCSE 關注的問題是 universal sentence embeddings,這在 NLP 領域是個基礎且重要的問題。SimCSE 提出一個應用 Contrastive Learning 的訓練方法,來訓練預訓練語言模型(如:BERT 或 RoBERTa),可以使用不管是 unlabeled 或 labeled data 來訓練 sentence embeddings。在使用 unlabeled data 進行 unsupervised learning 的情況下,SimCSE 在 STS(Semantic textual similarity)任務的表現上,不只是遠超其它之前提出的 unsupervised models,甚至能超越 supervised models,使用 labeled data 進行 supervised learning 則更不用說了,穩穩的成為 STS 任務的新 SOTA。如果將 SimCSE 訓練出的模型,遷移到其它任務進行微調,則表現也能比之前提出的其它方法有相當抑或好上一點的表現。
接下來筆者將慢慢講解 SimCSE,包括:
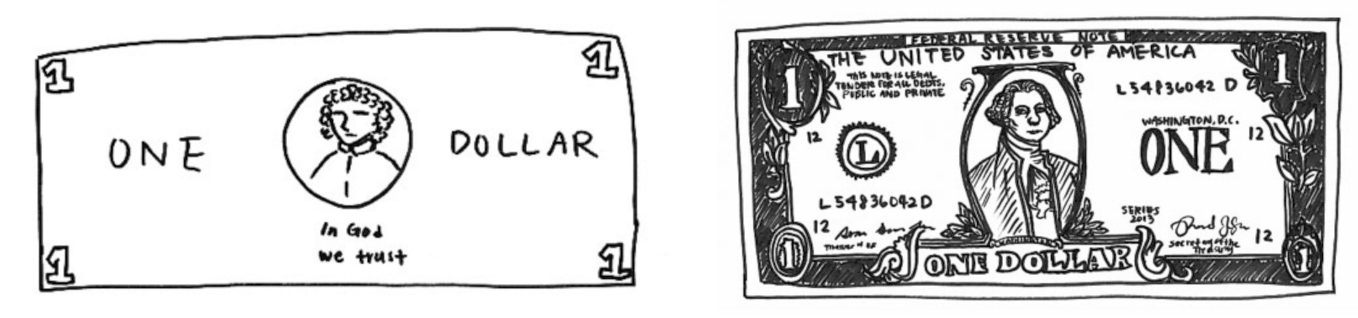
左:憑記憶畫出來的美元鈔票。右:在有美元鈔票的情況下畫出來的圖。
圖(2)說明了一件事,即使我們見過很多次鈔票,也無法重現出完美的鈔票,但是我們仍然能夠藉由某些關鍵特徵,就能輕易地辨別是否為鈔票。藉此,也就表示其實模型並不需要記住每一個細節,只要能擷取出關鍵特徵,就可以區分不同的東西,這就是 Contrastive Learning 的核心思想。

這裡藉由 SimCLR 圖(3)是怎麼做的,來簡單了解 CL。(1)先 sample 一些 data(batch);(2)對 batch 裡的 data 做不同的 augmentation;(3)一樣的 data 的 representation 要互吸,不一樣的要互斥,簡易流程就是這樣。一樣要拉近,不一樣要拉遠,這就是 CL 的目標。
接下來我們就來看看 SimCSE 是怎麼設計 CL 的訓練。
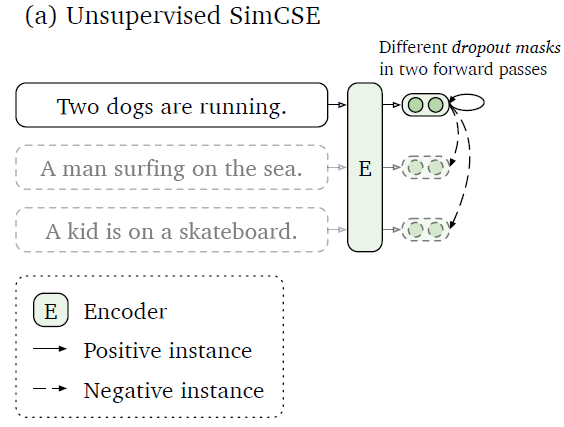
Unsupervised SimCSE 最關鍵的地方就是對如何建構 positive pair 的回答,對於 CV 領域有很多方法,如:cropping、flipping、distortion、rotation 這些 augmentation method,NLP 在近年也有許多方法被提出,如:word deletion、reordering、substitution。但作者發現這些方法反而會傷害到模型的表現,對此作者最後給出的答案非常簡單,那就是 dropout,dropout 可以作為 minimal data augmentation,並達到比之前其它的 augmentation 方法更好的表現。
所以要建構 positive pair 就非常簡單,作者直接利用原始 Transformer 裡的 dropout,讓一個句子分別通過模型兩次,因為 dropout 的關係,產出的兩個 sequence embedding 就會有些許的不同,從而變成一對 positive pair。接下來就是照上面所敘述的 CL 概念進行訓練就好。
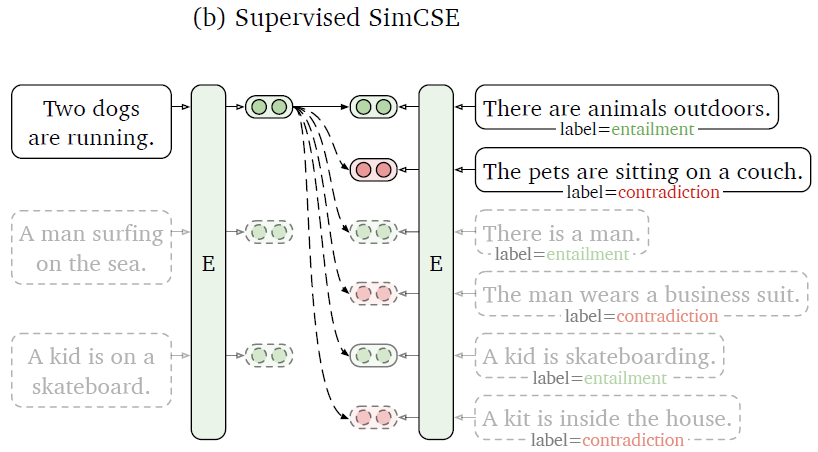
剛剛我們提到作者提出使用 dropout 來建構 positive pairs,並進行 unsupervised learning。接下來作者也研究了,如果我們使用 supervised datasets 來進行 supervised learning 能不能得到更好的表現?
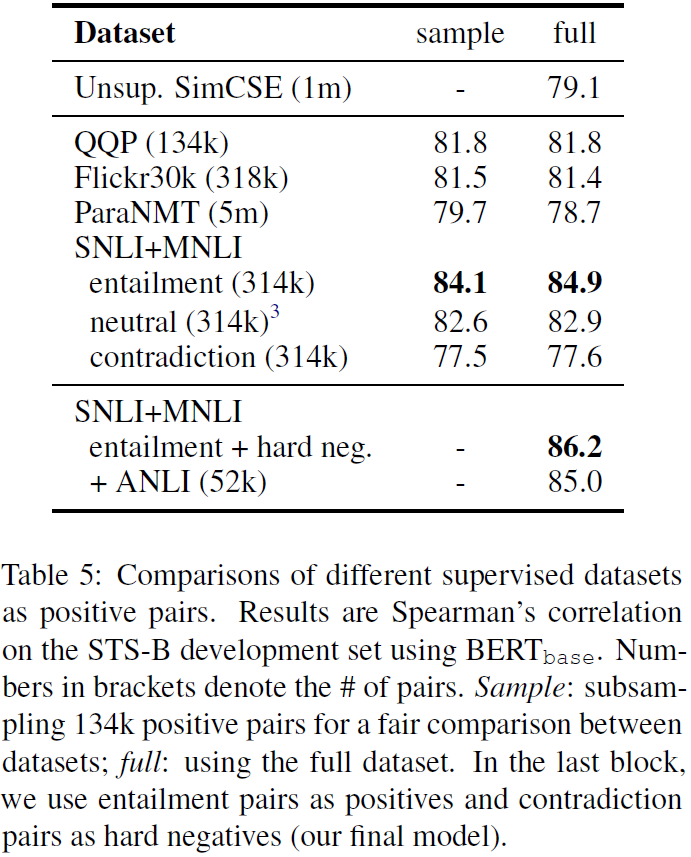
圖(6)回答了上述的問題,作者實驗了各種不同的 supervised dataset ,結果顯示使用 supervised dataset 訓練的確有效提高了模型的表現。並且作者提出利用 NLI datasets 的 contradiction pairs 當作 hard negative pairs,可以更進一步提高表現。作者也發現之前的方法(如:Sentence-BERT、StackSeq2Seq)常使用的 dual encoder framework 反而會降低模型的表現。
最後我們來看看 SimCSE 的各項表現。
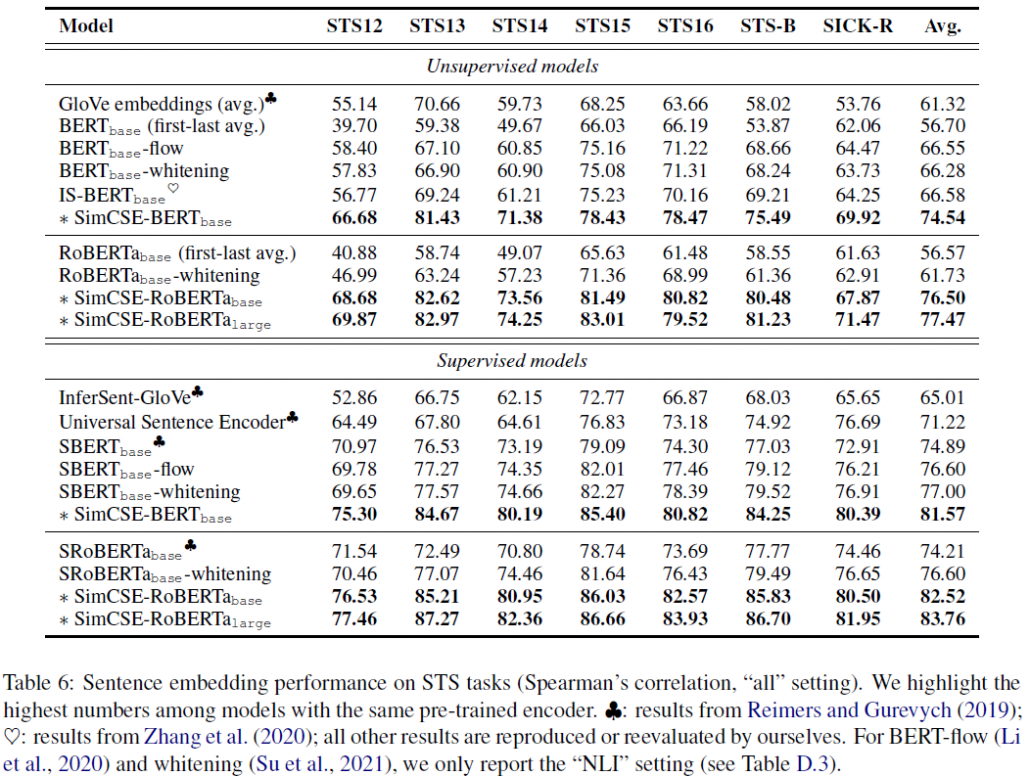
圖(7)顯示我們同時評估 supervised 和 unsupervised SimCSE 在每一個 STS 任務的表現。不管是哪一種 learning,SimCSE 在每個任務上表現相較之前都有所提升,綜合表現遠超之前的模型。SimCSE-RoBERTa_large 在只使用 unsupervised learning 下,表現甚至已經跟之前的 supervised model 旗鼓相當。
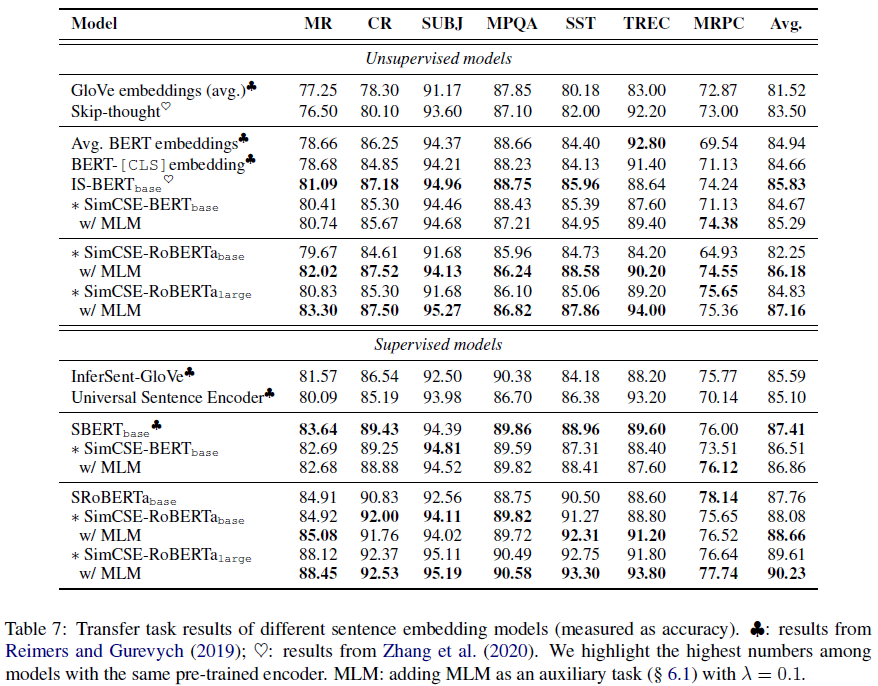
圖(9)顯示當我們遷移 SimCSE 去做其它 NLP 的下游任務,SimCSE 都能有相當或是更好一點的表現。作者也發現,如果在訓練時加入 MLM(Masked Language Model,克漏字)一起訓練,根據下游任務的不同,可能會有幫助或是傷害。
論文還有很多有趣的實驗,像是 pooler(如何產出 sequence embedding)的選擇、batch size、其它 unsupervised 方法在訓練的表現等等,因為篇幅關係,筆者就只取一部分講解,有興趣的人可以去看看原始論文。
SimCSE 提出利用 Contrastive Learning 進行訓練,可以使用不管是 Supervised 或 unsupervised learning 進行訓練,方法簡單暴力,在 STS 任務上成為新 SOTA。
Mixed precision training 是由百度與 NVIDIA 發表於 ICLR 2018 的論文,其提出一種訓練方法,使得在使用 half-precision(FP16) 訓練模型的情況下,也能達到與使用 single-precision(FP32) 訓練相當的表現,且得到加快訓練速度與降低顯存需求的效果。
在當今我們使用的模型變得越來越大,資料也越來越多,結果就是需要更高的算力與更多的顯存來訓練模型。
但當我們的資源不敷使用,銀彈也不夠直接買新設備時該怎麼辦呢?
這個時候就需要使用一些技法來設法降低資源需求,從而達到我們的目標,而 mixed precision training 就是其中一種方法。
影響 deep learning model performance 之因子有以下三種:
降低使用的精度,可以降低其中兩種因子的影響。
memory bandwidth 的壓力會降低,因為我們只需要更少的 bits 來存儲同樣的參數。
計算時間也會跟著降低,因為降低了計算的精度,從而得到了更高的 throughput。
不過降低精度也不是沒有副作用的,因為能夠表達的數值比原本更小。
由下圖所見,以 FP16 為例,它就只包含 FP32 的一半範圍,當我們需要使用到超過 FP16 的表達範圍時,便會產生問題,所以才需要提出 mixed precision training。
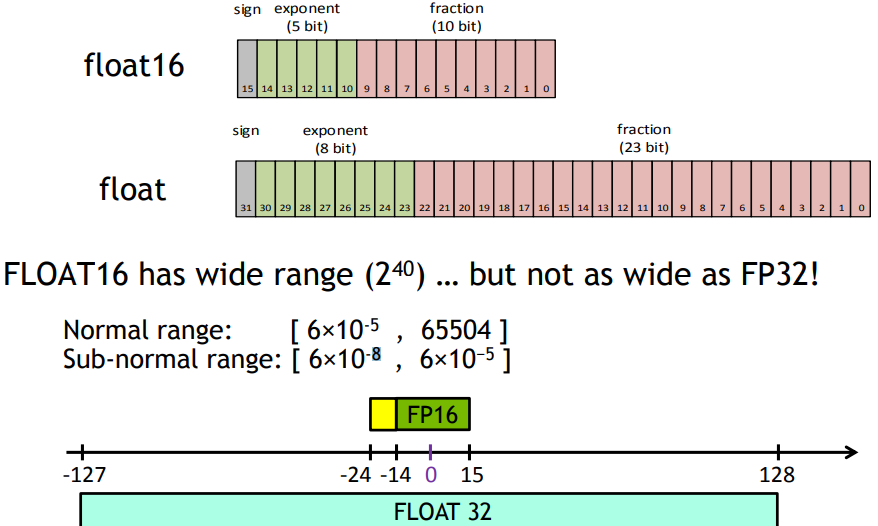
論文將使用 half-precision(FP16) 來訓練,而為了避免 FP16 可表達數值範圍較小產生的問題,利用了三種方法來避免模型表現下降:
在 mix precision training 中,weights、activations、gradients 都使用 FP16 儲存,並且有一份使用 FP32 儲存的 weight,我們稱它為 FP32 master weights。
訓練流程為,在每一次疊代開始時, FP32 的 weight 會被縮成 FP16,在經過 forward 跟 backward 之後,會得到 weight gradient,利用它去更新 FP32 的 weight,如此循環。
這樣我們可以保持相近於使用 FP32 網路的精確度,並對比使用 FP32 訓練,只需一半的儲存跟算力需求。
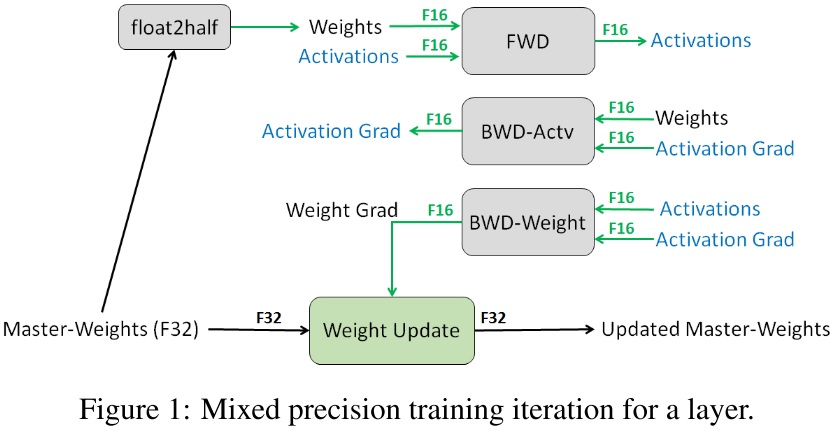
有兩個理由使我們需要 FP32 master weights。
第一,當我們的 weight gradient 乘上 learning rate 太小了,使之無法表示於 FP16,那就會變成零,weight 就無法更新了,由下圖可以看到約有 5% 的 weight gradient 小於 FP16 可表示的範圍而變成 0。
第二,當要更新的 weight 的值太大,即使要更新的 weight 值可以用 FP16 表示,當它更新的時候也會因為加法在進位的情況下,同樣使值變成 0。使用 FP32 weight 來更新則可避免遇到這些問題。
論文中也做了個實驗,訓練了一個模型,在使用與不使用 FP32 master weights 的情況下,對比使用 FP32 的收斂情況,由下圖可以看到使用 FP32 master weights 相比直接使用 FP32 有很相近的效果,而不使用 FP32 master weights 訓練效果就差非常多了。
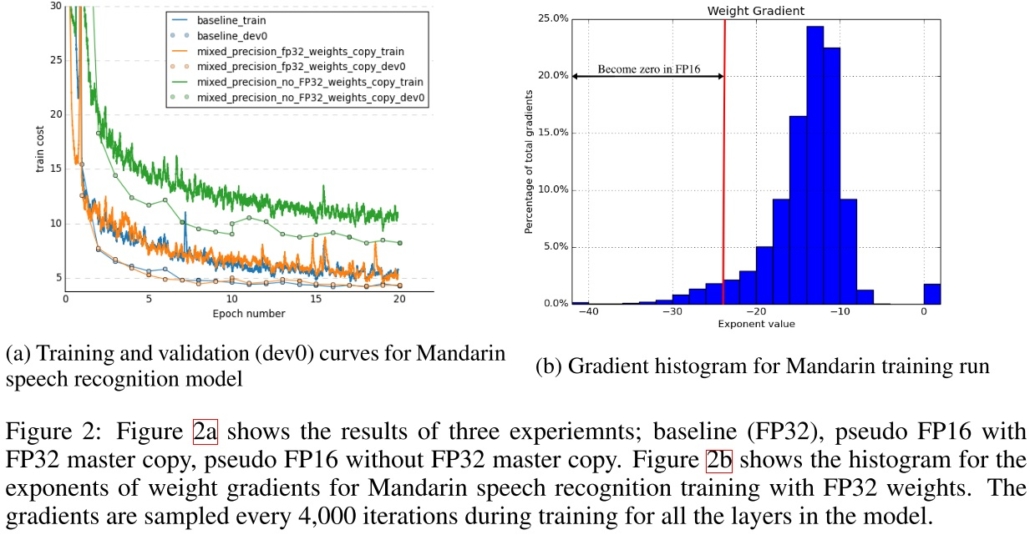
論文中指出大多數的 gradient 是負指數。並且做了個實驗來驗證,作者訓練了一個網路並且撈出每一層的 activation gradient 畫成圖,由下圖可以看到,大部分的 gradient 都是負的,並且很多小於 FP16 的表示範圍而變成了 0,另一個重要的部分則是,有一大部分 FP16 的可表示範圍沒有任何 gradient 的,這個就成了可以使用 loss scaling 的地方。
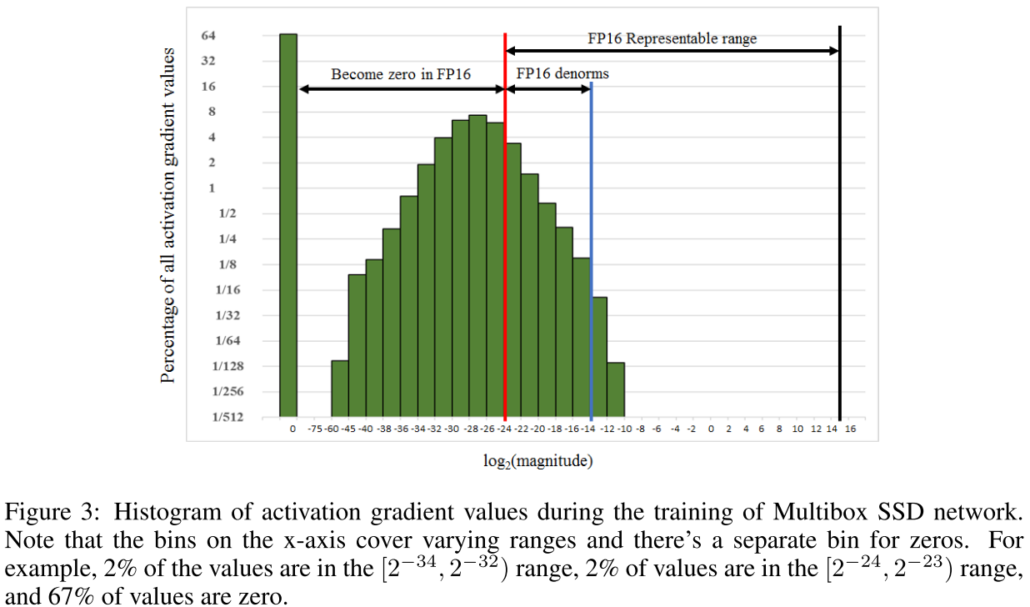
loss scaling 的想法很簡單,既然大多數 gradient 都很小,超過了 FP16 的表示範圍,那就乘上一個值讓它先變大,在更新時再縮回來不就好了。
具體來說,就是當 forward 計算出 loss 之後,把 loss 乘上一個值,這樣在 backward 時,就可以確保所有 gradient 都被一致的縮放。
然後在最後要更新 weight 時,我們在把 gradient unscaled 回來。如此就很簡單的減緩了上述的問題。
大多數的 deep learning network 主要使用以下三種計算:vector dot-products、reductions 與 point-wise operations。
作者提到,他們發現有些網路為了保持模型的準確度,需要將 FP16 相乘時累加到 FP32,然後在寫進內存前縮回 FP16。
在現在新的 NVIDIA GPU 上,NVIDIA 新增了 Tensor Cores,原生支援了這種計算。
讓我們總結一下 mixed precision training 的流程:
這裡就不細講實驗結果了,只要知道作者實驗了很多不同的網路,並且都達到與使用 FP32 訓練差不多的準確度就好,有興趣的人可以去察看原始論文。
最後在 pytorch 1.6 終於也原生支援了 mixed precision training,而不用再使用 Nvidia 出的 apex 來做,簡單了許多。
這裡也放上最基礎的在 pytorch 使用 mixed precision training 的方法。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as dset
from torchvision import datasets, transforms, models
from torch.cuda.amp import autocast, GradScaler
# create transform
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),]
)
# Data
trainSet = datasets.MNIST(root='MNIST', download=True, train=True, transform=transform)
trainLoader = dset.DataLoader(trainSet, batch_size=64, shuffle=True)
# Model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.base = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
)
self.fc = nn.Linear(32*7*7, 10)
def forward(self, input):
feature = self.base(input)
feature = feature.reshape(feature.size(0),-1)
output = self.fc(feature)
output = nn.functional.log_softmax(output, dim=1)
return output
model = Model().to('cuda:0')
optimizer = optim.SGD(model.parameters(), lr=1e-3)
criterion = nn.NLLLoss()
scaler = GradScaler()
for epoch in range(10):
for input, target in trainLoader:
input, target = input.to('cuda:0'), target.to('cuda:0')
optimizer.zero_grad()
with autocast():
output = model(input)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
我們簡單宣告了一個模型並使用 MNIST 資料集進行訓練,基本上對比原本的寫法,只需要加上幾行 code 就可以自動完成,是不是很方便呢。
如果想知道更多,可以去看看官方的 文件。


全台第一間 Apple 區域教育培訓中心 – 逢甲大學與 Straight A 晶盛科技攜手合作,舉辦 Apple「第四屆 APP 移動應用創新賽」,邀請全台大專院校學生激發創意思考與實作能力,以蘋果公司的產品及開發工具為基礎進行 iOS 系統設計開發,設計具創意與高實用性的 APP 作品。逢甲大學人工智慧研究中心成員組成團隊「你的護膚小天使」,設計以圖像處理進行膚況檢測的 APP「Beauty Agenda 膚況辨識養顏食療推薦系統」勇奪特獎。
「Beauty Agenda」的設計研發團隊「你的護膚小天使」,提倡透過天然食物的攝取,來取代瓶瓶罐罐的保養品及保健食品,經由 APP 圖像處理進行臉部膚質診斷,幫使用者找出膚況可能成因,並提供養顏清單食材,從日常飲食來打造自然美麗與健康;另一方面也與台灣有機小農合作,實施訂閱制食材配送,使用者可以直接訂閱所需之食材宅配到府。Beauty Agenda 不僅為使用者提供了個人化的服務,同時也建立銷售通路來幫助台灣小農,獨特的創新想法與商業模式,搭配簡單直覺的 APP 介面設計,讓 Beauty Agenda 在競賽中掄元,取得前進大中華區「2020 年 APP 移動應用創新賽」總決賽的門票。
美的定義一直隨著時代在改變,近年來,無論男、女都非常注重肌膚的保養及健康。人體肌膚所需的營養都是從食物中獲得,維持肌膚健康的第一步,就是均衡攝取各式各樣的食物,因此週週現採配送的訂閱式蔬果箱於近年來搶攻市場。而 Beauty Agenda 正是將美麗與健康結合,透過臉部偵測系統分析膚況,並提供相對應建議補充的營養及食材,此外,更進一步可以讓使用者可以直接購買,宅配到府,方便又新鮮,讓大家都能吃出由內而外的好膚質。
「APP 移動應用創新賽」自 2017 年首度在台創辦以來,成為台灣校園團隊展現創意思考與實作絕佳的舞台,堪稱是一年一度最盛大的 APP 程式設計競賽。逢甲大學人工智慧研究中心於 2019 年成立,目標為人才培育及企業合作,減少學界與業界間的學用落差,此次組成團隊參與競賽,一舉奪下特獎,無論對成員或人工智慧研究中心都是極大的肯定,期望「你的護膚小天使」在大中華區「2020 年 APP 移動應用創新賽」總決賽中能夠再創佳績。


繼科技部宣示台灣進入AI元年後,全台大大小小的企業皆紛紛投入AI技術的研究、網羅AI人才,健豪印刷張訓嘉總經理深知人工智慧的重要性,與逢甲大學所簽訂之人工智慧技術共同發展備忘錄,將以長期捐贈的形式,資助逢甲大學人工智慧研究中心之成立與營運,昨 109 年 7 月 30 日於逢甲大學舉辦『產學合作期中成果展示暨捐贈儀式』,由張總經理將首期啟動經費新台幣八百萬元捐贈予逢甲大學,在逢甲大學,則由李秉乾校長代表接受,並感謝健豪印刷對逢甲大學的肯定與支持。
逢甲大學人工智慧研究中心許懷中主任更於現場展示了健豪印刷產學合作的成果,許主任表示,印刷品在送印的過程中可能由於軟體版本或其他因素,造成最終印刷檔案與原始稿件有差異,而中心就是要在送印前抓出這些問題,完成健豪印刷印前流程全自動化的最後一哩路。「我們的模型可以分辨圖形的差異是文字的毛邊或是缺失的陰影,準確度超過 99%,可以協助健豪節省75% 的人力成本,讓審稿人員能夠更專注於問題稿件。」許主任驕傲的說,「這些都是中心夥伴的研究成果,我們不僅要解決企業的問題,更要利用產學合作的優勢,培養優秀的技術人才進入企業。」
逢甲大學人工智慧研究中心成立於108年10月,設有資料工程與應用、電腦視覺、生醫工程及自然語言處理與理解等四個研究群,主要任務為企業產學合作與人才培育,未來更希望可以透過課程、講座等活動推廣人工智慧技術,進而引導中部地區產業技術升級。
近年來學用落差一直是企業與大學畢業生最大的痛處,面對即將到來的人工智慧時代,企業對於人才缺口甚是憂心,逢甲大學人工智慧研究中心日後將積極投入更多產學專案,藉由將企業的資源與問題引入學校,彌平學用落差,成為業界與學界間的橋樑,大步邁向即將到來的人工智慧時代。
逢甲人工智慧教師社群
Convolutional Neural Network and Image Processing
講師:陳伯維


