

Text Summarization with Pretrained Encoders:如何將 BERT 應用在 Text Summarization Task 上
Abstract
不管要解任何問題,從 BERT、ELMo、GPT 等等,這些大家琅琅上口的各種預訓練模型開始進行,在 NLP 領域基本已經變成起手式。筆者今天要介紹的論文 Text Summarization with Pretrained Encoders 也不例外,論文分析如何有效地將 BERT 應用在 text summarization task 上,以及預訓練模型對 text summarization task 的影響,並且提出一個可以做 extractive 和 abstractive models 的通用框架。
論文的 contribution 為:
- 分析 document encoding 對於 summarization task 的重要性
- 提出如何有效地應用預訓練模型在不管是 extractive 或 abstractive 下的 summarization task
接下來,筆者將先快速介紹跟 text summarization task 相關的各種名詞,幫助不熟悉此領域的讀者了解讀懂論文需要的知識,以防鴨子聽雷的狀況,之後再進入正題,熟悉的讀者則可直接跳往正題閱讀。
Background
BERT
BERT 這個由 Google 在 2019 所提出的模型相信大家都不陌生,在提出後就刷了各種任務的榜,成了 NLP 領域無人不知無人不曉的模型。論文中對 BERT 的輸入進行了修改,讓其更好的對應 summarization task 的特性,為了對比,筆者先複習一下原版的 BERT 的輸入。
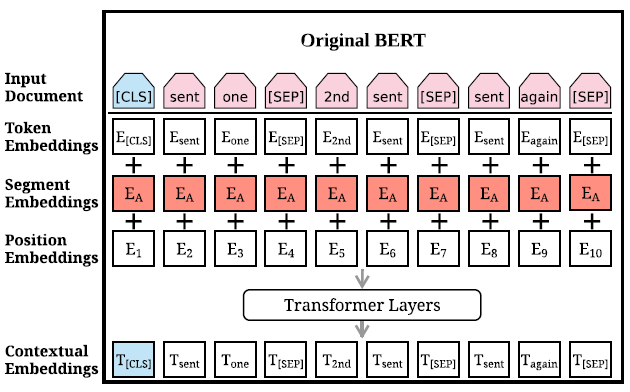
一開始要輸入的 document 會經過處理加上兩種特殊符號[CLS]與[SEP]。[CLS]插在整個 document 的頭,代表整個 document 的開始,[SEP]插在 document 中每個 sentence 的尾,用來區分不同的 sentence。經過處理後,document 表示成 \(Input \, document = [w_1, w_2, \dots , w_n]\),\(w_i\) 代表 document 裡的第 \(i\) 個 token。在 BERT 裡,每個 token \(w_i\) 總共會有三種 embedding,token embeddings 代表 token 的意思,segmentation embeddings 代表 token 屬於哪個句子,position embeddings 代表 token 在 sentence 中的位置,將這三種 embedding 相加起來就變成了 BERT 的輸入 \(X = [x_1, x_2, \dots , x_n]\),之後丟進由幾層 Transformer Layers 疊起來組成的 Encoder:
\(\widetilde{h}^l = LN(h^{l-1} + MHAtt(h^{l-1}))\)
\(h^l = LN(\widetilde{h}^l+ FFN(\widetilde{h}^l))\)
h 是 hidden states,\(h^0 = X\);LN 是 Layer normalization;MHAtt 是 multi-head attention;\(l\) 是疊幾層 Transformer Layers 的層數。最終 BERT 會輸出 \(T = [t_1, t_2, \dots , t_n]\),每個 \(t_i\) 是擁有語意資訊的 word embedding。
Extractive and Abstractive Summarization
在 text summarization 有兩種不同的系統,分別是 extractive 與 abstractive 兩種。
extractive summarization 為藉由在文章裡找尋重要的句子,並把找出來的句子接在一起,當作這篇文章的 summary。在模型訓練上,則是當做 sentence classification 的任務,藉由分類每個句子是否為重要句子,來得到要做為 summary 的句子。
abstractive summarization 則是將原始文章餵給模型吃,並直接吐出一段 summary 的方法,是一個 sequence to sequence 的問題。abstractive 相較 extractive 困難的點為,abstractive 需要能夠產生原本不存在於文章的詞彙或句子,並且要符合語言的規則。
Fine-tuning BERT for Summarization
在上面筆者簡單複習了 BERT 與 summarization task 的兩種方式,現在就讓我們來看看如何微調 BERT,在任務上做得更好吧。
Summarization Encoder
論文中指出,將 BERT 直接應用於 summarization,顯然是會有問題的。首先在做 summarization 上,我們通常會使用 sentence embedding 來做相關任務,但 BERT 的訓練方式 MLM(克漏字、填空),學習重點是放在 word embedding 上,而不是 sentence embedding ,另一個問題是即便 segmentation embeddings 可以區分不同的句子,在原始 BERT 中只有使用 sentence pair 進行訓練,就是兩個句子組合在一起,在 summarization 上,則通常需要使用大於兩個的多句子接在一起當作輸入。
鑒於上面提到的問題,論文修改了原始 BERT 的輸入方式,讓 BERT 可以更好的處理 summarization,並提出針對 summarization task 的 BERTSUM。
在 BERTSUM 中,document 裡的每一段 sentence 前面都會額外插入一個[CLS]符號,這裡這麼做有兩個目的,一個是為了凸顯個別句子(individual sentences),另一個是,作者會將這些[CLS]符號的輸出當作每段句子的 sentence embedding,用於後續的預測任務。segmentation embeddings 也被修改為 interval segment embeddings,用於更好的區分多句子,規則是 \(sent_i\) 會根據它是奇數句或偶數句來決定是 \(E_A\) 或 \(E_B\)。舉個例子,一個 document 包含 \([sent_1, sent_2, sent_3, sent_4, sent_5]\),那麼這個 document 的 segment embeddings 為 \([E_A, E_B, E_A, E_B, E_A]\)。經過這樣的設計,模型就能學習到不管是句子表示,相鄰的句子,或是整個 document 的意思。
論文中分別提出如何將 BERTSUM 應用於 Extractive 和 Abstractive Summarization 上,接下來就讓我們來一個一個看看是怎麼做的。
BERTSUMEXT:BERTSUM of Extractive Summarization
在 background 中,筆者介紹過 Extractive Summarization 其實就是對每個句子做二元分類,分類是否要拿來作 summary,所以我們要做的就是把每段句子的 sentence embedding 取出來並丟進分類器進行預測。論文中介紹了在 BERTSUM 上,再加入了幾層 Transformer layers 來做 Extractive Summarization 的模型,並命名為 BERTSUMEXT。整個模型構造很簡單,以下開始介紹:
在 BERTSUM 中,剛剛筆者說過每段句子的 sentence embedding 由[CLS]符號的輸出而來。因此,我們可以將 BERTSUM 的輸入看做是很多個句子,\(d\) 代表一個 document 包含句子 \([sent_1, sent_2, \dots ,sent_m]\),\(sent_i\) 是在 document 裡的第 \(i\) 個句子,第 \(i\) 個[CLS]符號的輸出寫作 vector \(t_i\) ,是 \(sent_i\) 的 sentence embedding。通過 BERTSUM 我們有了每個句子的 sentence embedding,接下來就是將它們丟進額外加入的 \(l\) 層 Transformer layers,獲取 document-level 的特徵:
\(\widetilde{h}^l = LN(h^{l-1} + MHAtt(h^{l-1}))\)
\(h^l = LN(\widetilde{h}^l+ FFN(\widetilde{h}^l))\)
h 是 hidden states,\(h^0 = PosEmb(T)\);\(T\) 代表 BERTSUM 輸出的 sentence embeddings。
模型的最後就是一個簡單的 sigmoid classifier:
\(\hat{y}_i = \sigma(W_0h_i^L+b_o)\)
\(h^L_i\) 就是 Transformer第 \(L\) 層 \(sent_i\) 的輸出。
BERTSUMABS、BERTSUMEXTABS:BERTSUM of Abstractive Summarization
在 Abstractive Summarization 中,這篇論文使用的模型是普通的 encoder-decoder 架構。encoder 是 pretrained 過的 BERTSUM,decoder 則是隨機初始化的 6 層 Transformer layers。這裡有個小重點,encoder 與 decoder 必須使用不同的 optimizer 來訓練,原因是,如果直接一起訓練的話,當 decoder 還在 underfitting 時,經過 pre-trained 的 encoder 可能已經 overfitting 了。因此,訓練這個網路時,encoder 會使用較小的 learning rate,decoder 則使用較大的 learning rate,讓整個訓練更穩定。這種架構與訓練方式的網路,論文稱為 BERTSUMABS。
論文中也同時提出一個兩階段式 fine-tune 方法,稱為 BERTSUMEXTABS。根據先前的經驗(Gehrmann et al., 2018; Li et al., 2018),先做 extractive summarization 可以提升模型在 abstractive summarization task 的表現,所以 BERTSUMEXTABS 會先在 extractive summarization task 上 fine-tuned encoder ,然後再在 abstractive summarization task 上 fine-tuned 第二次。這樣訓練出來的模型稱為 BERTSUMEXTABS。
Result

論文總共實驗了三種不同的資料集,它們的 summary 風格各不相同,可能是文章的重點摘要、一句總結,或由原文剪貼而成,這樣我們就可以評估模型在不同 summary 形式下的表現。
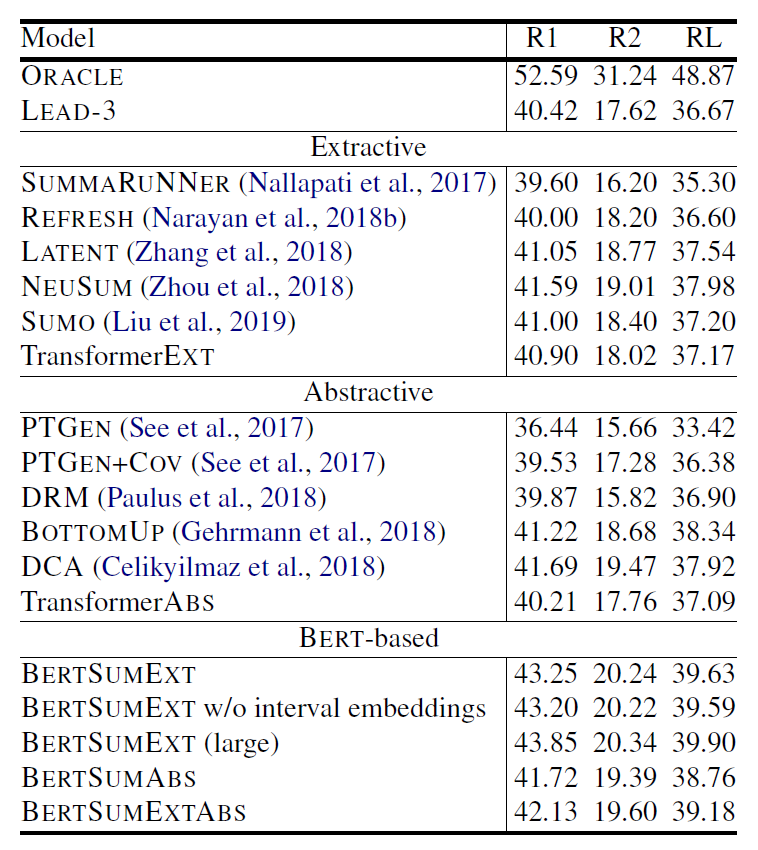
表 (1)第一行的 ORACLE 是 extractive ORACLE system,在這裡用來當作表現的 upper bound。LEAD-3 則是直接選文章的前三句當作 summary 的表現。TransformerEXT 代表架構與 BERTSUMEXT 一樣,但是沒有經過 pre-trained,直接在 summarization task 上做訓練,TransformerABS 同理。由表中可以觀察到,BERSUM 相比之前的模型表現都有提升,但也沒有提升太多,原因讓我們繼續看看別的資料集的實驗結果就會知道。
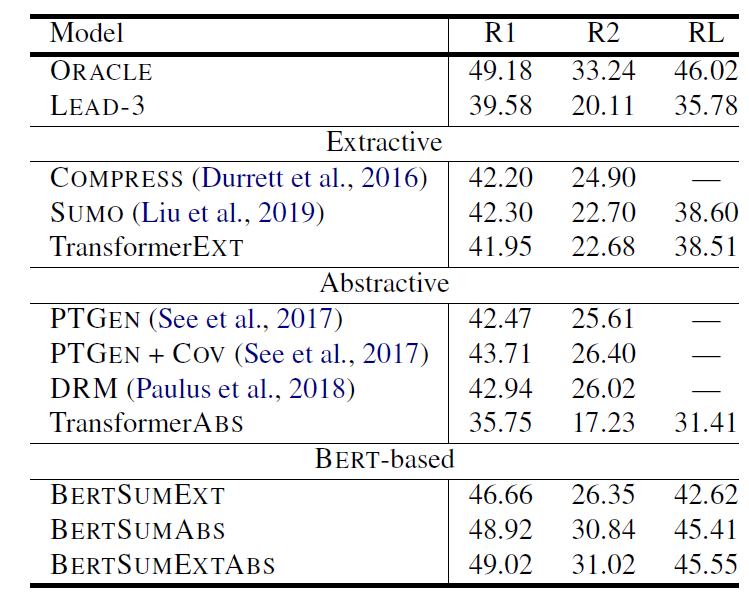
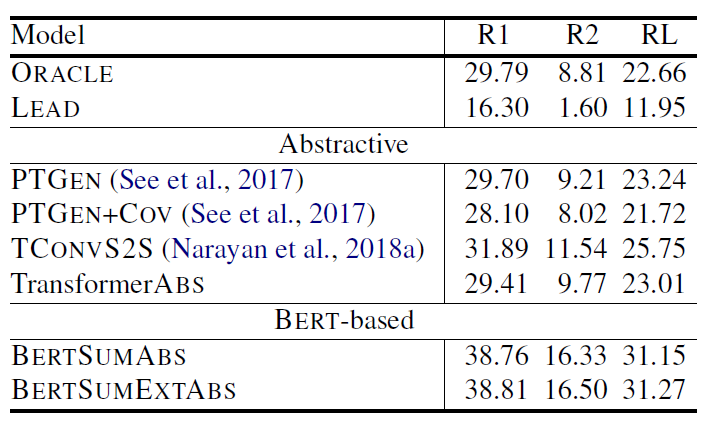
當我們一次把 BERTSUM 在 CNN/DailyMail(表 1)、NYT(表 2)跟 XSum(表 3)的表現拿出來比較,原因就很明顯了。有發現嗎?在 percent of novel bi-grams in gold summary 低的資料集,BERTSUM 的表現就顯得普通,沒有驚人的表現,跟 LEAD-3 的表現也差距不大,並且 BERTSUMEXT 會是表現較好的模型,這就顯示了因為 gold summary 可以大幅地從原文中拼貼出來,所以模型之間的表現就拉不開差距。所以在這種發現下,如果去看 BERTSUM 在 XSum 的表現,BERTSUM 的厲害就徹底展現出來了,不僅贏過了 ORACLE system,表現相比其他模型也大幅上升。
另一個值得關注的點則是 pre-trained 的重要性,對比有 pre-trained 與沒有 pre-trained 的模型,可以發現表現差距很大,尤其在 abstractive summarization 上,最多可以有超過 10% 的差距,再一次呼應論文標題的 with Pretrained Encoders 這句話。
Conclusion
本文帶讀者了解了 Text Summarization with Pretrained Encoders 這篇論文,其基於 BERT 進行改良,改造成適合用於 summarization task 的架構,並提出 BERTSUMEXT、BERTSUMABS、BERTSUMEXTABS 三種模型,用簡單的方式,大幅提升了 BERT 在 summarization task 上的表現。

發表評論
Want to join the discussion?Feel free to contribute!